XiaoMi-AI文件搜索系统
World File Search SystemSequence


人工智能的范围和顺序
3.1.H:学生将批判性地评估数据隐私相关问题,包括未经同意收集个人数据的道德问题以及基于人工智能的监控的影响。他们将分析旨在保护日益数据驱动的世界中个人隐私的法律和道德框架。 2. 安全问题 3.2.P:学生将描述虚拟助手和机器人等人工智能工具如何帮助人们保持安全,例如通过呼救或关灯。他们将确定哪些人工智能工具需要正常工作才能保证人们的安全,以及成年人如何帮助确保正确使用它们。

MCP-1的DNA序列
DNA sequence of scFv-11K2 ATGGAAGTTCAGCTGCAGCAGAGCGGTGCAGAACTGGTTAAAGCCGGTGCAAGCGTTAAACTGA GCTGTCCGGCAAGCGGTCTGAACATCAAAGATACCTATATGCATTGGGTTAAACAGCGTCCGGAA cagggtctggaatggatgatgtcgtcgtcgtcggaaatggcaaatgcaaatccaaatccaaatttgatccagaaatt tcagggtaaagcaaccatccatcgcagcagcagcagcagcagcagcagcagcagcagcagcataTctgcagcagcagctgcagcagcccccccccccccccc tgaccagcgaagataccgcagttactactgcccgtgcgtgtgtgtgtgttttttttttttttttttgattgattggg gtcagggggggcaccccccccgtgaccgttagcgcgcgcgcgcggcggcggcgggcgggcgggcggcggcggcggcggcggcggcggcgggggggggggtc GGGCGGTGGCGGATCGGATGGGATGATATCGATGATGATGACCCCCCAGCAGCAGCAGCTTTAGC gttagcctgggtgtgtgtgtgtgtgtgttaccatcctgtaacctgtaaaagccaccaccccaccacccaccagcaagatttatatataataataatcgcctggcctggga TGGTATCAGAAACCGGGCGCCGCGCGCGCGCGCTGCTGCGGCGGTGCAACCAGCCTGGAAAC CGGTGTGTGTTGTCCGCGCGTTTTTAGCGGTTAGCGGTTTTCTTTCTCTGGTGGTGGTGGTAAAAGAGATATACCTACCTGAGAGAGCATACCAGCAGCCCCTCCTCTCTCT GCAGACCGAAGAGATGCACTATTATTGCCAGCAGTTTTTTTGGCGCACCGCCGTATACCTTTGGTGGGTGGCACCAAACTGAATAATGAATAATAAACTAAACGTGCCGCCGCGCGCGCGGGCGGGCACCACCACCATCATCATCACCACCACCACCATCATTAA


basespace序列中心
在决定将基因组数据移至基于云的分析和存储时,安全性至关重要。在Basespace序列中心中,数据通过各种物理,电子和管理措施保护数据。使用AES256标准1对上传的数据进行加密,并受传输层安全性(TLS)保护。BASESPACE序列中心中的数据托管在Amazon Web Services(AWS)上,该服务符合各种行业所接受的安全标准。2企业订阅提供了额外的安全性。为企业客户提供了自己的域以及使用自己的安全断言标记语言(SAML)2.0支持的身份验证服务来管理用户和密码。BASESPACE序列中心还支持企业客户在《健康保险可移植性和问责制法》(HIPAA)3中受监管的环境(BAA)。有关更多信息,请阅读Basespace序列中心安全性和隐私安全性简介。4

事件顺序 - 国防部
任务 1. 1989 年 7 月 - 1990 年 11 月,学生,第 14 学生中队,哥伦布空军基地,密西西比州。 2. 1990 年 11 月 - 1993 年 11 月,机组指挥官、训练副主管、标准化和评估主管,第 6 太空预警中队,科德角空军基地,马萨诸塞州。 3. 1993 年 11 月 - 1994 年 12 月,雷达系统官,第 21 作战支援中队,彼得森空军基地,科罗拉多州。 4. 1994 年 12 月 - 1995 年 7 月,执行官,第 21 作战大队,彼得森空军基地,科罗拉多州。 5. 1995 年 8 月 - 1997 年 5 月,空军实习生,美国空军总部和乔治华盛顿大学,华盛顿特区。 6. 1997 年 8 月 - 1999 年 6 月,UHF F/O 卫星飞行器操作员、机组指挥官和作战飞行指挥官,第 3 7. 1999 年 6 月 - 2000 年 7 月,第 22 空间作战中队作战官,科罗拉多州施里弗空军基地 8. 2000 年 8 月 - 2001 年 6 月,学生,空军指挥参谋学院,阿拉巴马州麦克斯韦空军基地 9. 2001 年 7 月 - 2002 年 6 月,学生,高级航空航天研究学院,阿拉巴马州麦克斯韦空军基地 10. 2002 年 7 月 - 2003 年 6 月,区域政策官员,美国空间司令部总部和美国西部战略司令部,科罗拉多州彼得森空军基地 11. 2003 年 6 月 - 2004 年 6 月,指挥官特别助理,美国战略司令部总部,内布拉斯加州奥福特空军基地 12. 2004 年 7 月 - 2005 年 7 月,指挥官,第 13 空间预警中队,Clear AFS,阿拉斯加13. 2005 年 7 月 - 2006 年 5 月,兰德公司空军研究员,加利福尼亚州圣莫尼卡 14. 2006 年 6 月 - 2008 年 6 月,第 614 空天作战中心指挥官兼联合


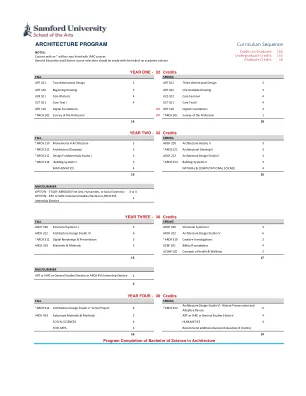
2024 年课程序列手册
• CHI 201 中级汉语 I • CHI 202 中级汉语 II • FRE 201 中级法语 I • FRE 202 中级法语 II • JPN 201 中级日语 I • JPN 202 中级日语 II • LAT 201 中级拉丁语 I • LAT 202 中级拉丁语 II • POR201 中级葡萄牙语 I • POR 202 中级葡萄牙语 II • SPA201 中级西班牙语 I • SPA202 中级西班牙语 II • ASL 201 美国手语 I • ASL202 美国手语 II 学生必须以最低“D”的成绩完成 202 才能满足核心课程要求。学生可以完成世界语言文学系批准的其他语言。

专利和序列搜索指南和...
序列数据也已成为无处不在的全球创新工具,当今的任何发展级别的利益相关者或创新者都无法忽略它。即使位于发展中国家或最不发达国家(LDC),或在土著人民或当地社区(IPLC)中,今天与GRS合作的GR利益相关者和创新者也需要处理序列数据搜索和管理工具,即我们在其他技术领域中使用库以及文字处理器的研究和文字处理器的方式。他们对利用这些图书馆目录,文字处理器和搜索工具的熟悉程度越多,即使这些库科学创新的进步就越多,即使这些创新可能一开始就不熟悉或略微令人生畏。序列数据正在以指数级的速度增长,并且通过国际核苷酸的公共数据库将其可访问性民主化