XiaoMi-AI文件搜索系统
World File Search SystemVLM

Minecraft的增强学习友好视觉语言模型
摘要。AI研究界的基本任务之一是建立一个自主体现的代理,该代理可以在各种各样的任务中实现高级绩效。但是,为所有开放式任务获取或手动设计奖励是不现实的。在本文中,我们提出了一种新颖的跨模式对比学习框架 - 夹子4MC,旨在学习加强学习(RL)友好的视觉语言模型(VLM),该模型(VLM)充当开放式任务的无限奖励功能。仅利用视频片段和语言提示之间的模拟性不友好,因为标准VLMS只能在粗级上捕获相似性。为了实现RL友好性,我们将任务完成学位纳入了VLM培训目标,因为这些信息可以根据区分不同状态之间的重要性。此外,我们根据MinedoJo提供的大规模YouTube数据库提供整洁的YouTube数据集。具体来说,两轮过滤操作保证数据集涵盖了足够的基本信息,并且视频文本对高度相关。经验,我们证明了所提出的方法与基准相比,在RL任务上可以更好地进行性能。代码和数据集可在https://github.com/pku-rl/clip4mc上找到。

mu cai -cs.wisc.edu-威斯康星大学 - 麦迪逊分校
研究兴趣我的研究兴趣在于计算机视觉和机器学习的交集。i最近在多模式生成模型的应用和基本限制上工作,包括多模态大语言模型(MLLM,VLM)和多模式嵌入模型(Clip,dinov2)。我对视频,视觉提示和3D理解特别感兴趣。
![arxiv:2501.07769v1 [cs.lg] 2025年1月14日](/simg/2\27caac521555f28e8d68c7195ac7286b0f5dcb90.webp)
arxiv:2501.07769v1 [cs.lg] 2025年1月14日
视觉语言模型(VLM)具有重大的概括能力,并且对VLM的迅速学习引起了人们的极大关注,因为它能够使预先训练的VLM适应既定的下游任务。但是,现有的研究主要集中于单模式提示或单向模态互动,从而忽略了视觉和语言方式之间的相互作用所带来的强大对齐效应。为此,我们提出了一种新颖的及时学习方法,称为B i方向i nteraction p rompt(BMIP),该方法通过学习注意力层的信息,增强了与简单的Inforormation聚合方法相比,通过学习注意力层的信息,增强了训练层的信息,增强了运动层的信息,增强了训练层的信息,增强了双向信息。为了评估迅速学习方法的有效性,我们提出了一个更现实的评估范式,称为开放世界概括,补充了广泛采用的跨数据库转移和域通用任务。在各种数据集上进行的综合实验表明,BMIP不仅比所有三种评估范式的当前最新方法都胜过当前的最新方法,而且还足够灵活,可以与其他基于及时的及时性能增强的方法结合使用。

在固体基础上建立视觉模型的模型
视觉模型(VLM)的最新进步在弥合计算机视觉和自然语言处理之间的差距方面取得了重大飞跃。然而,传统的VLM通过对有限和嘈杂的图像文本对进行对比学习训练,通常缺乏空间和语言的理解,可以很好地推广到密集的视觉任务或更少的通用语言。我们的方法,坚实的基础剪辑(SF-CLIP),通过隐式建立对经过大量单峰数据训练的基础模型的可靠的视觉和语言理解来避免此问题。sf-clip将对比的图像文本预测与大型基础文本和视觉模型的掩盖知识蒸馏。这种方法可以指导我们的VLM开发强大的文本和图像表示。结果,SF-CLIP显示出异常的零射击分类精度,并增强了图像和文本检索能力,为在YFCC15M和CC12M上训练的VIT-B/16的新最新状态。此外,在语义分割任务中,密集的每个斑点监督增强了我们的零射击和线性探针的性能。我们模型的一个了不起的方面是它的多语言能力,尽管主要接受了英语数据的培训,但通过多种语言的强劲检索结果证明了这一点。我们通过选择性地应用掩盖的蒸馏和教师单词嵌入的继承来实现所有这些改进,而无需牺牲培训效率。
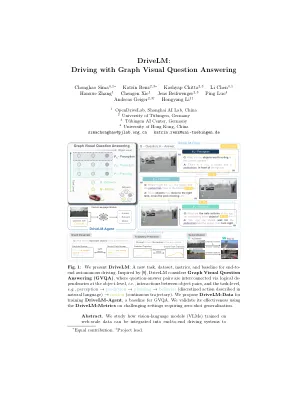
drivelm:用图形驾驶视觉问题回答
增强概括并实现与人类用户的互动性。最近的方法可以使VLM通过单轮视觉问题答案(VQA)适应VLM,但人类驾驶员在多个步骤中的决策原因。从关键对象的本地化开始,人类在采取行动之前估计相互作用。关键洞察力是,通过我们提出的任务,图形VQA,我们在其中建模了图形结构的理由,通过感知,预测和计划问题 - 答案对,我们获得了一个合适的代理任务来模仿人类的推理。我们实例化基于Nuscenes和Carla建立的数据集(DRIVELM-DATA),并提出了一种基于VLM的基线方法(Drivelm-Agent),用于共同执行图形VQA和端到端驾驶。实验表明,Graph VQA提供了一个简单的原则性框架,用于推理驾驶场景,而Drivelm-Data为这项任务提供了具有挑战性的基准。与最新的驾驶特定架构相比,我们的Drivelm-Agent基线端到端自动驾驶竞争性驾驶。值得注意的是,当在看不见的传感器配置上评估其零射击时,其好处是明显的。我们的问题上的消融研究表明,绩效增长来自图表结构中对质量检查对质量检查的丰富注释。所有数据,模型和官方评估服务器均可在https://github.com/opendrivelab/drivelm上找到。

drivelm:用图形驾驶视觉问题回答
增强概括并实现与人类用户的互动性。最近的方法可以使VLM通过单轮视觉问题答案(VQA)适应VLM,但人类驾驶员在多个步骤中的决策原因。从关键对象的本地化开始,人类在采取行动之前估计相互作用。关键洞察力是,通过我们提出的任务,图形VQA,我们在其中建模了图形结构的理由,通过感知,预测和计划问题 - 答案对,我们获得了一个合适的代理任务来模仿人类的推理。我们实例化基于Nuscenes和Carla建立的数据集(DRIVELM-DATA),并提出了一种基于VLM的基线方法(Drivelm-Agent),用于共同执行图形VQA和端到端驾驶。实验表明,Graph VQA提供了一个简单的原则性框架,用于推理驾驶场景,而Drivelm-Data为这项任务提供了具有挑战性的基准。与最新的驾驶特定架构相比,我们的Drivelm-Agent基线端到端自动驾驶竞争性驾驶。值得注意的是,当在看不见的传感器配置上评估其零射击时,其好处是明显的。我们的问题上的消融研究表明,绩效增长来自图表结构中对质量检查对质量检查的丰富注释。所有数据,模型和官方评估服务器均可在https://github.com/opendrivelab/drivelm上找到。
![ARXIV:2407.05342V1 [CS.CV] 7 JUL 2024
在中的重建和未结构结构共存
评估人类协作:...
arxiv:2407.07035v1 [CS.CL] 9月9日2024
观察非易失性磁性 - 热切换...
旋转角动量的光子准晶体
土匪的集中差异隐私
在AI-... 中优化以人为中心的目标
算法什么时候应该辞职? AI治理的提案
通过预测分析增强网络安全
基于事件触发的增强学习基于超级可靠的低延迟v2x通信的联合资源分配](/simg/3\3a456051cbc8ba5176d68ebda8e39d4dbc06c013.webp)
ARXIV:2407.05342V1 [CS.CV] 7 JUL 2024 在中的重建和未结构结构共存 评估人类协作:... arxiv:2407.07035v1 [CS.CL] 9月9日2024 观察非易失性磁性 - 热切换... 旋转角动量的光子准晶体 土匪的集中差异隐私 在AI-... 中优化以人为中心的目标 算法什么时候应该辞职? AI治理的提案 通过预测分析增强网络安全 基于事件触发的增强学习基于超级可靠的低延迟v2x通信的联合资源分配
摘要。本研究解决了域级逐步学习问题,这是一种现实但具有挑战性的持续学习场景,在该方案中,域分布和目标类别跨任务各不相同。为处理这些不同的任务,引入了预训练的视力语言模型(VLM),以实现其强大的推广性。但是,这会引起一个新问题:在适应新任务时,预先训练的VLMS中编码的知识可能会受到干扰,从而损害了它们固有的零射击能力。现有方法通过在额外的数据集上使用知识蒸馏来调整VLM来解决它,这需要大量计算。为了有效地解决此问题,我们提出了无知的无干扰知识集成(DIKI)框架,从避免避免信息干扰的角度来保留对VLM的预训练的知识。具体来说,我们设计了一种完全残留的机制,可以将新学习的知识注入冷冻的骨干中,同时引发对预训练的知识的不利影响最小。此外,此残差属性可以使我们的分布感知的集成校准方案明确控制来自看不见的分布的测试数据的信息植入过程。实验表明,我们的二基仅使用训练有素的参数超过了当前的最新方法,并且需要较少的训练时间。代码可在以下网址找到:https://github.com/lloongx/diki。

外周血细胞图像分析的语言模型
摘要本文研究了视觉模型(VLM)在外周血细胞自动形态学分析中的应用。虽然手动显微镜分析仍然是血液学诊断的金标准,但它既耗时又可能会受到观察者间的变化。这项工作旨在开发和评估能够从微观图像中对血细胞进行准确的形态描述的微调VLM。我们的方法论包括三个主要阶段:首先,我们创建了一个合成数据集,该数据集由10,000个外周血细胞图像与专家制作的形态描述配对。第二,我们在三个开源VLMS上使用低级适应性(LORA)和量化Lora(Qlora)进行了微调方法:Llama 3.2,Qwen和Smovlm。最后,我们开发了一个基于Web的界面,用于实用部署。的结果表明,在预先调整后所有模型的所有模型中都有显着改善,QWEN的性能最高(BLEU:0.22,Rouge-1:0.55,Bertscore F1:0.89)。为了确保可访问性并实现正在进行的评估,该模型已被部署为网络空间的Web应用程序,使研究社区可自由使用。我们得出的结论是,微调的VLM可以有效地分析外周血细胞形态,从而为血液学分析提供了标准化的潜力。这项工作建立了一个框架,可以将视觉模型改编为专业的医疗成像任务,这对改善临床环境中的诊断工作流程的影响。完整的实现可在GitHub

navila_paper.pdf
执行视觉和语言导航(VLN)的能力已成为现代机器人系统中的基础组成部分。使用VLN,一个机器人有望根据语言说明[1-6]在没有提供的地图的情况下在看不见的环境周围导航。这不仅为人类提供了更好的相互作用,而且还通过语言加强了跨场所的概括。在本文中,我们通过腿部机器人(例如四倍或人形生物)进一步扩展了VLN的研究。使用腿而不是轮子可以使机器人在更具挑战性和混乱的场景中导航。如图1,我们的机器人可以在狭窄的人行道上浏览一个凌乱的实验室空间,从房屋中的房间过渡到房间,以及解决户外挑战性的环境,例如带有小岩石,孔和槽的不均匀地形。要将语言转换为动作,机器人需要对输入语言进行推理,并执行闭环计划以及低级控制。随着大语言模型(LLM)和视觉模型(VLM)的最新进展,已经开发了几个端到端视觉语言动作(VLA)系统[7-9]。这些系统对具有大规模的机器人操纵演示的通用Propose VLM微调,以产生低级动作。虽然在单个模型中统一推理和执行令人着迷,并且表现出令人鼓舞的结果,但值得深入研究以下问题:是否有更好的方法来代表量化的低级命令以外的动作?毕竟,LLM和VLM主要接受了自然语言的培训。当我们需要将推理转换为精确的非语言行动时,统一推理和执行变得具有挑战性。受到VLM [10,11]的最新进展的启发,我们提出了纳维拉(Navila)的提议,这是一个针对腿部机器人VLN的两个级别框架:VLM的两级框架,可以很好地输出中级动作(VLA),以“右转30度”的策略,以及训练的范围,以“转向30度”。VLA的中级动作输出无需低级命令传达位置和方向信息。该框架的优点是三个方面:(i)通过将低级执行与VLA分解,可以通过交换低级策略来在不同的机器人上应用相同的VLA; (ii)将动作表示为中级语言指令,可以通过不同的数据源进行VLA培训,包括真实的人类视频和推理质量检查任务。这可以增强推理功能,而不会过度拟合特定的低级命令,并可以利用现实世界数据进行概括; (iii)Navila在两个不同的时间尺度上运行:VLA通常是一个大型且计算密集的模型,以较低的频率运行,提供高级导航命令;运动策略实时运行。这种双频方法允许

通过提示大语言来发现对象属性
我们提出了一个由VLM和LLMs组成的p API API,以及一组机器人控制功能。使用此API和自然语言查询提示时,LLM会生成一个程序来积极识别给定输入图像的属性。