XiaoMi-AI文件搜索系统
World File Search Systemcaptions
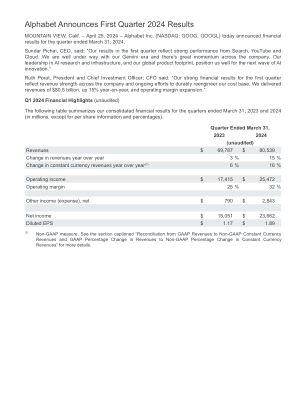
GOOG 展览 99.1 2024 年第一季度
本新闻稿可能包含涉及风险和不确定性的前瞻性陈述。实际结果可能与预测结果存在重大差异,报告结果不应被视为未来业绩的指标。可能导致实际结果与预测结果不同的潜在风险和不确定性包括但不限于我们截至 2023 年 12 月 31 日的 10-K 表年度报告中“风险因素”和“管理层对财务状况和经营成果的讨论和分析”标题下包含的风险和不确定性,这些报告已提交给美国证券交易委员会,可在我们的投资者关系网站 http://abc.xyz/investor 和美国证券交易委员会网站 www.sec.gov 上查阅。其他信息还将列在我们截至 2024 年 3 月 31 日的季度报告 10-Q 表上,并可能列在我们向美国证券交易委员会提交的其他报告和文件中。本新闻稿及其附件中提供的所有信息截至 2024 年 4 月 25 日。不应过分依赖本新闻稿中的前瞻性陈述,这些陈述基于我们截至本新闻稿发布之日掌握的信息。除非法律要求,否则我们不承担更新此信息的义务。

图像字幕结合GAN训练方法
摘要 在图像数量庞大、人们无法快速检索所需信息的当今世界,我们迫切需要一种更加简便、人性化的图像理解方式,图像字幕应运而生。图像字幕,顾名思义,就是通过分析理解图像信息,生成特定图像的自然语言描述,近年来被广泛应用于图文交叉研究、婴幼儿教育、弱势群体帮扶以及产业界的青睐,产生了许多优秀的研究成果。目前对图像字幕的评价基本基于BLUE、CIDEr等客观评价指标,容易导致生成的字幕无法接近人类语言表达,而GAN思想的引入使得我们能够采用对抗训练这种新的方法来对生成的字幕进行评价,评价模块更加自然、全面。考虑到对图像逼真度的要求,本课题提出了一种基于GAN的图像描述。引入Attention机制来提高图像保真度,使得生成的字幕更加准确,更接近人类的语言表达。

控制...
视觉语言模型(例如剪辑)对零拍或无标签预测的各种下流任务显示出很大的影响。但是,当涉及到低级视觉时,例如图像恢复其性能会由于输入损坏而急剧下降。在本文中,我们提出了一种退化感知的视觉模型(DA-CLIP),以更好地将预验证的视觉模型转移到低级视觉任务中,作为用于图像恢复的多任务框架。更具体地说,DA-CLIP训练一个额外的控制器,该控制器适应固定的剪辑图像编码器以预测高质量的特征嵌入。通过通过交叉注意将床上用品集成到图像恢复网络中,我们能够试行该模型以学习高保真图像重建。控制器本身还将输出与输入的真实损坏相匹配的降级功能,从而为不同的降解类型产生天然分类器。此外,我们将混合降解数据集与合成字幕结构为DA-CLIP训练。我们的方法在特定于降解和统一的图像恢复任务上提高了最先进的性能,显示出具有大规模预处理视觉模型促使图像恢复的有希望的方向。我们的代码可在https://github.com/algolzw/daclip-uir上找到。
![arxiv:2305.04536v2 [CS.CV] 2024年6月18日](/simg/9\954ae78a6188e649adb8f41247881a246a455e8d.webp)
arxiv:2305.04536v2 [CS.CV] 2024年6月18日
长尾的多标签视觉识别(LTML)任务是由于标签共发生和不平衡的数据分布,这是一项极具挑战性的任务。在这项工作中,我们为LTML提出了一个统一的框架,即促使特定于班级的嵌入损失(LMPT)进行调整,从而通过结合文本和im im Im operational数据来捕获语义功能相互作用,并在头部和尾部同步改进型号。具体来说,LMPT通过班级感知的软边距和重新投资介绍了嵌入式损失函数,以学习特定的班级上下文,并带有文本描述(字幕)的好处,这可以帮助建立类之间的语义关系,尤其是在头和尾部之间。fur-hoverore考虑到类失样的类别,分配平衡的损失被用作分类损失函数,以进一步提高尾部类别的性能而不会损害头部类别。在VOC-LT和可可-LT数据集上进行了广泛的实验,这表明我们的方法显着超过了先前的最新方法,而LTML中的零拍夹。我们的代码在https://github.com/richard-peng-xia/lmpt上完全公开。

lmpt:长尾多标签视觉识别的特定于类的嵌入损失
长尾的多标签视觉识别(LTML)任务是由于标签共发生和不平衡的数据分布,这是一项极具挑战性的任务。在这项工作中,我们为LTML提出了一个统一的框架,即促使特定于班级的嵌入损失(LMPT)进行调整,从而通过结合文本和im im Im operational数据来捕获语义功能相互作用,并在头部和尾部同步改进型号。具体来说,LMPT通过班级感知的软边距和重新投资介绍了嵌入式损失函数,以学习特定的班级上下文,并带有文本描述(字幕)的好处,这可以帮助建立类之间的语义关系,尤其是在头和尾部之间。fur-hoverore考虑到类失样的类别,分配平衡的损失被用作分类损失函数,以进一步提高尾部类别的性能而不会损害头部类别。在VOC-LT和可可-LT数据集上进行了广泛的实验,这表明我们的方法显着超过了先前的最新方法,而LTML中的零拍夹。我们的代码在https://github.com/richard-peng-xia/lmpt上完全公开。

Codewithzichao@DravidianLangTech-EACL2021:探索泰米尔语中模因分类的多模态变换器
近年来,随着社交媒体平台的繁荣,表情包逐渐成为网络交流的一部分。因此,检测表情包是否对个人或组织具有冒犯性对于确保互联网内容的多样性和可持续性至关重要。对表情包进行分类是否为恶意内容是一项具有挑战性的任务。此外,目前已经有很多工作集中在英语上(Truong 和 Lauw,2019 年;Xu 等,2019 年;Cai 等,2019 年),但针对泰米尔语的研究很少。泰米尔语表情包分类共享任务填补了这一空白。此共享任务的目标是检测从社交媒体平台收集的表情包是否为恶意内容。每个表情包都标有恶意或非恶意类别。此外,每张图片都嵌入了泰米尔语和拉丁字母的字幕转录。这是一个多模态分类任务,给定图像和文本对,系统必须将此对分类为 troll 或非 troll 类。在本文中,我们探索了一种用于泰米尔语 meme 分类的多模态转换器。根据图像和文本的特征,

AJP 报告作者说明
• 您必须提交手稿的电子版。我们不接受纸质版。 • 保持手稿格式简洁明了。我们将根据自己的风格设置您的手稿 — 不要试图“设计”文档。 • 手稿(包括标题页、摘要和关键词、正文、参考文献、图表标题和表格)应采用打字方式,使用 12 号字体双倍行距,四周留 1 英寸边距,并保存为一个文件。 • 每个图表应保存为单独的文件。请勿将图表嵌入手稿文件中。这需要 Thieme 制作部门进行特殊处理。 • 尽量减少缩写,并确保在文本中第一次使用缩写时解释所有缩写。 • 手稿应使用美式英语书写。 • 作者应使用国际单位制 (SI) 测量单位。为清晰起见,非公制等效单位可以放在 SI 测量单位后的括号中。 • 使用药物通用名称。您可以在括号中引用专有名称以及制造商的名称和位置。 • 在括号内注明稿件中提到的设备、药品和其他品牌材料的供应商和制造商,并提供公司名称和主要地点。

Alphabet 宣布 2023 年第四季度和财年业绩
本新闻稿可能包含涉及风险和不确定性的前瞻性陈述。实际结果可能与预测结果存在重大差异,报告结果不应被视为未来业绩的指标。可能导致实际结果与预测结果不同的潜在风险和不确定性包括但不限于我们截至 2022 年 12 月 31 日的 10-K 表年度报告和我们截至 2023 年 9 月 30 日的最新 10-Q 表季度报告中“风险因素”和“管理层对财务状况和经营成果的讨论和分析”标题下包含的风险和不确定性,这些报告已提交给美国证券交易委员会,可在我们的投资者关系网站 http://abc.xyz/investor 和美国证券交易委员会网站 www.sec.gov 上查阅。其他信息还将列在我们截至 2023 年 12 月 31 日的 10-K 表年度报告中,并可能列在我们向美国证券交易委员会提交的其他报告和文件中。本新闻稿及其附件中提供的所有信息截至 2024 年 1 月 30 日。不应过分依赖本新闻稿中的前瞻性陈述,这些陈述基于我们截至本新闻稿发布之日掌握的信息。除非法律要求,否则我们不承担更新此信息的义务。

议程 - 理事会会议 - 星期二 - 2007 年 5 月 15 日 - 下午 1:30
议程 - 市议会会议 - 星期二 - 2007 年 5 月 15 日 - 下午 1:30 市议会会议厅 - 二楼 - 市政厅 901 BAGBY - 德克萨斯州休斯顿 祈祷和效忠宣誓 - 市议员布朗 下午 1:30 - 点名通过上次会议记录 下午 2:00 - 公众发言人 - 根据市议会规则 8,市议会将听取公众成员的意见;发布此议程时要求发言的人员的姓名和主题已附上;随后请求发言的人员的姓名和主题可从市秘书办公室获得 下午 5:00 - 休会重新召开 星期三 - 2007 年 5 月 16 日 - 上午 9:00 市秘书将在会议开始前宣读议程项目的描述或标题 市长报告 - 2008 财政年度预算 同意议程编号 1 至 41 杂项 - 编号 1 至 3 1. 休斯顿国际礼宾联盟主任请求与印度泰米尔纳德邦金奈(以前的马德拉斯)建立姐妹城市关系 2. 消防队长建议批准向姐妹城市厄瓜多尔瓜亚基尔捐赠过时/多余的消防设备

视觉和语言模型是否共享概念?向量空间对齐研究
另一些人则认为,语言模型具有推理语义,但没有指称语义(Rapaport,2002;Sahlgren 和 Carlsson,2021;Piantadosi 和 Hill,2022),3 而一些人则认为,至少对于直接对话的聊天机器人来说,一种外部指称语义是可能的(Cappelen 和 Dever,2021;Butlin,2021;Mollo 和 Milli`ere,2023;Mandelkern 和 Linzen,2023)。然而,大多数研究人员都认为,语言模型“缺乏将话语与世界联系起来的能力”(Bender 和 Koller,2020),因为它们没有“世界的心理模型”(Mitchell 和 Krakauer,2023)。这项研究提供了相反的证据:语言模型和计算机视觉模型 (VM) 是在独立的数据源上进行训练的(至少对于无监督的计算机视觉模型而言)。唯一的共同偏见来源是世界。如果 LM 和 VM 表现出相似性,那一定是因为它们都对世界进行了建模。我们通过测量不同 LM 和 VM 的几何形状的相似性来检查它们学习到的表示。我们始终发现,LM 越好,它们诱导的表示就越类似于计算机视觉模型诱导的表示。这两个空间之间的相似性使得我们能够从一组非常小的并行示例中将 VM 表示线性投影到语言空间并检索高度准确的字幕,如图 1 中的示例所示。