XiaoMi-AI文件搜索系统
World File Search Systemcombining

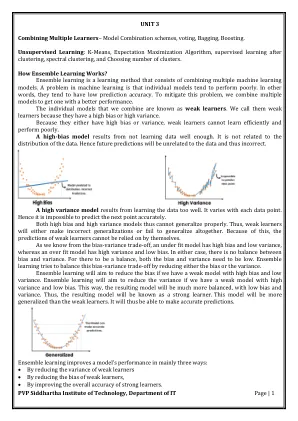
1单元3结合多个学习者
在训练阶段。可以通过在引导数据集中进行许多弱学习者来提高模型的性能。包装的一个例子是随机森林算法。合奏方法的类型•投票•行李(减少方差)•提升(减少偏见)•堆叠(改进的预测)结合了多个学习者: - 尽管不同的学习算法通常是成功的,但没有一个算法总是最准确的。现在,我们将讨论由相互补充的多个学习者组成的模型,以便通过将它们结合起来,我们获得了更高的准确性。模型组合方案: - 也有不同的方式组合多个基础学习者以生成最终输出多Expert组合: - 多Expert组合方法具有并行起作用的基础学习者。这些方法依次可以分为两者:在全局方法中,也称为学习者融合,给定输入,所有基础学习者都会生成


结合摄影测量的城市图像
关键词:组合、比较、影像、正射影像、校正、城市、可视化。摘要:多个科学界致力于使用摄影测量技术对城市地区进行建模。另一方面,随着高分辨率卫星的使用,城市地区的遥感技术也已存在数年。与此同时,从分析摄影测量向数字摄影测量的转变现在已非常有效。因此,遥感和摄影测量变得前所未有的紧密,这种趋势在相应的软件中也非常明显。遥感是需要空间和光谱信息的领域的宝贵工具。对于土地利用评估或区域尺度变化检测等主题,用于光学卫星图像的图像处理技术已证明其潜力。我们的团队熟悉使用摄影测量技术对城市地区进行建模的问题,通过整合卫星图像处理的知识扩展了其研究课题。为此,在与斯特拉斯堡 ENSAIS 测量系学生的实践工作中,我们使用摄影测量软件和遥感软件进行了调查。在创建由立体照片复原而来的数字地形模型后,将创建多个正射影像并将其拼接在一起。已尝试使用 o 并行执行地理编码和拼接图像的步骤

有针对性的α-疗法结合了Astatine-211和抗...
1 Nantes大学,CNRS, (S.G.); [C.M. <.m。 ); (F.G.); (N.C.); alliot@arronax-nantes.fr(c.a。 ); (J.G. ); (EC) 2 Nantes,CNR,CNR,CRCINE,F-4000 NANTES,法国; Severine.Water Lambot @Univ-Nantes.fr(S.M.-L。); (C.B. <.b。 ); (F.K.-B。) 3医院中心D是卖出的分区,F-85925法国岩石南部; Nantes,F-44000 Nantes,法国; 6意图分组,F-44800 Saint-Heblain,电话。 : + 33-228-080-21 Nantes大学,CNRS, (S.G.); [C.M. <.m。); (F.G.); (N.C.); alliot@arronax-nantes.fr(c.a。); (J.G.); (EC)2 Nantes,CNR,CNR,CRCINE,F-4000 NANTES,法国; Severine.Water Lambot @Univ-Nantes.fr(S.M.-L。); (C.B. <.b。); (F.K.-B。)3医院中心D是卖出的分区,F-85925法国岩石南部; Nantes,F-44000 Nantes,法国; 6意图分组,F-44800 Saint-Heblain,电话。: + 33-228-080-2

将治疗性疫苗与化疗相结合
利用免疫系统治疗癌症一直是肿瘤学研究的目标,现在癌症免疫疗法已在临床实践中得以实现 [1]。最近的临床成功已经改变了恶性和难治性癌症(如黑色素瘤和淋巴瘤)的治疗方法 [2]。最值得注意的是,检查点抑制剂能够显著提高转移性癌症患者的生存率,而常规疗法无法治愈此类患者 [3]。随着人们对耐受性、免疫力和免疫抑制如何调节抗肿瘤免疫反应的理解不断深入,以及靶向疗法的出现,这些成功表明,主动免疫疗法是癌症患者获得强大而持久免疫反应的一条途径 [4]。

组合流感和COVID-19疫苗接种(...
现在有一些疫苗已被批准在英国预防Covid-19。这些COVID-19疫苗的保护持续时间尚不清楚,但可能需要进一步的加强剂量才能继续保护。在对Covid-19的大量人中进行免疫挑战以及继续季节性流感(流感)疫苗接种时间表的需求,如果我们可以在同一任命下向人们提供同时的Covid-19-19-19-noce-19-19助推器和流感疫苗,那将是最好的。这意味着同一天接收两种疫苗,每只手臂中一次接种。这也意味着对于那些需要疫苗并减轻NHS负担的人来说,任命更少。因此,Comflucov研究的目的是查看诸如发烧和疲倦之类的副作用,当人们获得与当前推荐的流感疫苗同时获得第二剂Covid-19疫苗时会得到什么副作用。一起,我们还将考虑人们对两种疫苗的免疫反应。

结合监督和无监督机器学习
最后,Darktrace 还使用各种机器学习技术来自动执行调查工作流程中执行的重复且耗时的任务。通过分析专家网络分析师如何与 AI 的输出进行交互(例如他们如何分类威胁警报以及他们如何使用第三方来源),Darktrace 能够复制这些专家行为并自动执行某些分析师功能。这使得所有成熟度级别的分析师都能进行越来越高效和简化的调查。它还为安全团队提供了他们所需的关键时间,使他们能够专注于更高价值的战略工作,例如管理风险和专注于更广泛的业务改进。


结合工业 4.0 技术与...的方法
将工业 4.0 技术和 KPI 可靠性相结合以实现供应链绩效的方法 Yousra El Kihel a、Anne Zouggar Amrani a、Yves Ducq a、Driss Ameguouz b、Ahmed lfakir ca 波尔多大学,CNRS,IMS,UMR 5218,33405 Talence,法国;b 实验室 TSI,Univ USMBA,Fes,摩洛哥;c 生产部,PSA,肯尼特拉,摩洛哥 电子邮件:yousra.el-kihel@u-bordeaux.fr、anne.zouggar@u-bordeaux.fr、yves.ducq@u-bordeaux.fr、driss.amegouz@usmba.ac.ma、ahmad.lfakir@mpsa.com 摘要:在国际化的背景下,供应链变得越来越复杂,需要做出大量决策。供应链 (SC) 绩效的建模和测量已得到研究人员的广泛关注,然而工业 4.0 时代新技术的出现正在改变环境,并隐性影响供应链管理的关键绩效指标 (KPI)。尽管存在多种模型,但考虑到 KPI 的重要性以及同时包含工业 4.0 技术,没有一种模型是专门针对供应链运营管理的。本文提出了一种研究方法,针对一个参考模型来掌握供应链状态,并识别决策,称为 GRAILOG,从中构建一组 KPI 来支持不同的决策。然后描述和演示了一种称为 PPTechIP 的方法,用于引导和建议公司进行与构建可靠 KPI 相关的工业 4.0 转型。PPTechIP 基于一组雷达,这些雷达基于 GRAILOG 模型,分为供应链的不同决策级别和功能。计算进步潜力并协助经理做出决策。拥抱工业 4.0 时代的 PSA(法国汽车制造商)被选中实施该模型。使用建议的方法,结果为 PSA 的控制指标提供了一些有趣的见解。大数据、增强现实和协作机器人引起了 PSA 的高度关注,并被判定为继续跟进的先行技术,而云计算则被判定为一种警示技术,必须谨慎考虑过度投资。关键词、供应链管理、关键绩效指标、工业 4.0、技术、汽车行业