XiaoMi-AI文件搜索系统
World File Search Systemlang

在生命的尽头探索使用抗塑性药物的使用:一组评估终端中的频率,模式和方法的评论
警告。 访问本文内容的访问是基于接受以下创意共享许可证确定的使用条件的条件:访问本文内容的访问是基于接受以下创意共享许可证确定的使用条件的条件:

2024 年西巴尔干地区竞争力展望
资料来源:欧盟委员会 (2023),欧洲创新记分牌,https://op.europa.eu/en/web/eu-law-and-publications/publication-detail/-/publication/04797497-25de-11ee-a2d3-01aa75ed71a1;欧盟统计局 (2024),“过去四周按性别划分的成年人学习参与情况”,https://ec.europa.eu/eurostat/databrowser/view/sdg_04_60/default/table?lang=en&category=t_educ.t_educ _part。

妊娠糖尿病的健康饮食
行动计划的目标是加强人际关系,并与改善土著人民的健康经历和成果的共同目标一起工作。分享我们在这次旅程中学到的知识,并提高人们对文化上适当的护理的认识,该区域与数字故事讲述专家Mike Lang合作创建了一系列土著患者故事。

等待发布:2024年中更新
14加拿大政府,2024年国家库存报告(2024),附件10:加拿大经济部门的加拿大温室气体排放表,1990 - 2022年,表A10-2。可在环境和气候变化可用加拿大数据目录,“加拿大的官方温室气库”。 https://data- donnees.az.ec.gc.ca/data/substances/monitor/canada-s-fcial-greenhouse-greenhouse-gas-gas-inventory/b-comenticector/?lang = eng = en
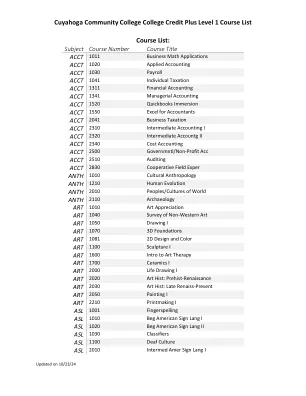
大学学分加一级课程列表
课程列表:科目 课程编号 课程名称 ACCT 1011 商业数学应用 ACCT 1020 应用会计 ACCT 1030 工资单 ACCT 1041 个人税务 ACCT 1311 财务会计 ACCT 1341 管理会计 ACCT 1520 Quickbooks Immersion ACCT 1550 会计 Excel ACCT 2041 商业税务 ACCT 2310 中级会计 I ACCT 2320 中级会计 II ACCT 2340 成本会计 ACCT 2500 政府/非营利会计 ACCT 2510 审计 ACCT 2830 合作领域专家 ANTH 1010 文化人类学 ANTH 1210 人类进化 ANTH 2010 世界民族/文化 ANTH 2110 考古学 ART 1010 艺术欣赏 艺术1040 非西方艺术概览 ART 1050 素描 I ART 1070 3D 基础 ART 1081 2D 设计和色彩 ART 1100 雕塑 I ART 1600 艺术治疗入门 ART 1700 陶瓷 I ART 2000 素描 I ART 2020 艺术史:史前 - 文艺复兴 ART 2030 艺术史:文艺复兴晚期 - 现在 ART 2050 绘画 I ART 2210 版画 I ASL 1001 手指拼写 ASL 1010 初级美国手语 I ASL 1020 初级美国手语 II ASL 1030 分类器 ASL 1100 聋人文化 ASL 2010 中级美国手语 I

血管系统及其对伤口发育和护理的影响:需要准确的血管评估
Meyer,A.,Schilling,A.,Kott,M.,Rother,U.,Lang,W。,&Regus,S。(2018)。 在末期肾脏疾病和临界肢体缺血患者中,膝盖动作的开放性与血管内血管内血管造成。 血管和血管内手术,52(8),613-620。 doi:10.1177/i5385744i8789036 Olivieri,B.,Yates,T。E.,Vianna,S.,Adenikinju,O. (2018年12月)。 在最前沿:血管内专家的伤口护理。 semin介入辐射。 35(5),406-426。 doi:10.1055/s-0038-1676342Meyer,A.,Schilling,A.,Kott,M.,Rother,U.,Lang,W。,&Regus,S。(2018)。在末期肾脏疾病和临界肢体缺血患者中,膝盖动作的开放性与血管内血管内血管造成。血管和血管内手术,52(8),613-620。 doi:10.1177/i5385744i8789036 Olivieri,B.,Yates,T。E.,Vianna,S.,Adenikinju,O.(2018年12月)。在最前沿:血管内专家的伤口护理。semin介入辐射。35(5),406-426。 doi:10.1055/s-0038-1676342

2。方案分析 - 关键实践点
6外部报告的示例包括SASB标准(https://www.sasb.org/standards/standards/download/?lang=ja-jp),该标准在77个部门中确定了环境,社会和治理问题,以及WBCSD对诸如wbcsd发出的诸如诸如wbcsd的范围的范围内的界面,以及工具,油气和加油,供应,油,油,油,油,油,油,油,油,油,油,以及化学,油和加油的。 https://climatescenariocatalogue.org/)


分布式可再生能源助力可持续发展
1 https://pib.gov.in/PressReleaseIframePage.aspx?PRID=1987752#:~:text=In%20August%202022%2C%20India%20更新,增强至50%25%20by%202030。 (截至 2024 年 2 月 19 日) 2 https://pib.gov.in/PressReleseDetail.aspx?PRID=1883915(截至 2024 年 2 月 19 日) 3 https://pib.gov.in/PressReleaseIframePage.aspx?PRID=1993550#:~:text=INCOME%2C%202023%2D24-,Indian%20 economy%20is%20to%20grow%20by%20a%20robust%207.3%25%20in,double%20digits%20growth%20of%- 2010.7%25。 (截至 2024 年 2 月 19 日)4 https://www.globaldata.com/data-insights/macroeconomic/urbanization-rate-in-india-2096096/#:~:text=India%20 had%20an%20urbanization%20rate%20of%201.34%25%20in%202021.,2011%2C%20between%202010%20and%202-021。 (截至 2024 年 2 月 19 日) 5 https://cea.nic.in/dashboard/?lang=en(截至 2024 年 2 月 19 日) 6 https://cea.nic.in/dashboard/?lang=en(截至 2024 年 2 月 19 日) 7 https://pib.gov.in/FeaturesDeatils.aspx?NoteId=151141&ModuleId%20=%202(截至 2024 年 2 月 19 日) 8 https://mnre.gov.in/physical-progress/(截至 2024 年 2 月 19 日) 9 兑换率为 1 美元 = 82 印度卢比 10 https://pib.gov.in/PressReleaseIframePage.aspx?PRID=2005596(截至 2024 年 2 月 19 日)
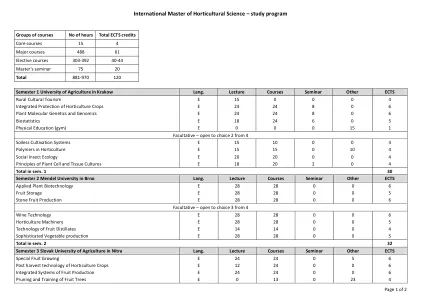
国际园艺科学硕士 - 研究计划
学期1个克拉科夫·朗的农业大学。讲座课程研讨会其他教育农村文化旅游E 15 0 0 0 4 4综合保护园艺作物E 24 24 8 0 6植物分子遗传学和基因组学E 24 24 8 0 6生物统计学e 18 24 6 0 6 0 24 6 0 5体育教育(体育社会昆虫生态E 20 20 0 0 4植物细胞和组织培养的原理E 18 20 2 0 4 SEM总计。1 30个学期2 Mendel University在Brno Lang。Lecture Courses Seminar Other ECTS Applied Plant Biotechnology E 28 28 0 0 6 Fruit Storage E 28 28 0 0 5 Stone Fruit Production E 28 28 0 0 6 Facultative – open to choice 3 from 4 Wine Technology E 28 28 0 0 6 Horticulture Machinery E 28 28 0 0 5 Technology of Fruit Distillates E 14 14 0 0 4 Sophisticated Vegetable production E 28 28 0 0 5 Total in sem.2 32学期3尼特拉·朗(Nitra Lang)的斯洛伐克农业大学。讲座课程研讨会其他特殊果实种植E 24 24 0 5 6园艺作物的收获后技术E 12 24 0 0 6果实生产的集成系统E 24 24 0 0 0 6果树的修剪和培训e 0 13 0 23 0 23 4