XiaoMi-AI文件搜索系统
World File Search System合成图像

用于检测 AI 生成图像的百万级基准
生成模型生成摄影图像的非凡能力加剧了人们对虚假信息传播的担忧,从而导致对能够区分人工智能生成的假图像和真实图像的检测器的需求。然而,缺乏包含来自最先进图像生成器的图像的大型数据集,这对此类检测器的开发构成了障碍。在本文中,我们介绍了 GenImage 数据集,它具有以下优点:1)图像丰富,包括超过一百万对人工智能生成的假图像和收集的真实图像。2)图像内容丰富,涵盖广泛的图像类别。3)最先进的生成器,使用先进的扩散模型和 GAN 合成图像。上述优势使在 GenImage 上训练的检测器经过彻底的评估,并表现出对各种图像的强大适用性。我们对数据集进行了全面分析,并提出了两个任务来评估检测方法在模拟真实场景中的表现。跨生成器图像分类任务衡量了在一个生成器上训练的检测器在其他生成器上测试时的性能。降级图像分类任务评估了检测器处理降级图像(例如低分辨率、模糊和压缩图像)的能力。借助 GenImage 数据集,与现行方法相比,研究人员可以有效地加快开发和评估更优秀的 AI 生成图像检测器。

建筑资产管理中的人工智能:...
摘要:建筑环境约占全球温室气体排放的 40%,是气候变化和可持续性的关键因素。与此同时,其他行业(如制造业)采用人工智能 (AI) 来解决复杂的非线性问题,以减少浪费、效率低下和污染。因此,建筑、工程和建筑界的许多研究工作最近都尝试将人工智能引入建筑资产管理 (AM) 流程。由于 AM 涵盖了广泛的学科,因此需要概述几种人工智能应用、当前的研究差距和趋势。在此背景下,本研究首次对建筑资产管理的人工智能进行了最先进的研究。使用文献计量工具分析了总共 578 篇论文,以确定知名机构、主题和期刊。定量分析有助于确定 AM 研究最多的领域以及应用了哪些人工智能技术。通过深入阅读在文献计量分析中筛选文章摘要选出的 83 篇最相关的研究,进一步研究了这些领域。结果显示,能源管理、状况评估、风险管理和项目管理领域有许多应用。最后,文献综述确定了三个主要趋势,可以作为从业者或研究人员未来研究的参考点:数字孪生、用于数据增强的生成对抗网络(带有合成图像)和深度强化学习。
![arXiv:2209.03177v1 [eess.IV] 2022 年 9 月 7 日](/simg/f\fa3ee8171c3333978c39d246479d5573a87f0728.webp)
arXiv:2209.03177v1 [eess.IV] 2022 年 9 月 7 日
摘要。可以使用医学成像数据研究人体解剖学、形态学和相关疾病。然而,由于管理和隐私问题、数据所有权和获取成本,医学成像数据的访问受到限制,从而限制了我们了解人体的能力。解决这个问题的一个可能方法是创建一个模型,该模型能够学习,然后根据特定的相关特征(例如年龄、性别和疾病状况)生成人体的合成图像。最近,以神经网络形式出现的深度生成模型已用于创建自然场景的合成二维图像。然而,由于数据稀缺以及算法和计算限制,生成具有正确解剖形态的高分辨率三维体积图像数据的能力受到阻碍。这项工作提出了一个生成模型,该模型可以扩展以生成解剖学正确、高分辨率和逼真的人脑图像,并具有进行进一步下游分析所需的质量。生成无限量数据的能力不仅能够实现大规模人体解剖学和病理学研究,而不会危及患者隐私,而且还能显著推动异常检测、模态合成、有限数据下的学习以及公平且合乎道德的人工智能领域的研究。代码和训练模型可在以下网址获取:https://github.com/AmigoLab/SynthAnatomy。
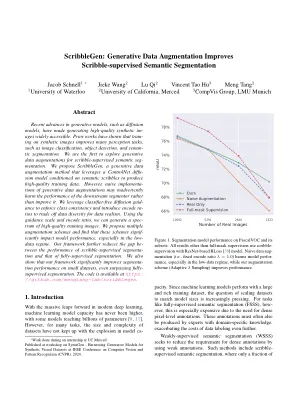
生成数据增强改善涂鸦 -
生成模型(例如扩散模型)的最新进展使生成高质量的合成IMEGES可以广泛访问。先前的作品表明,对合成图像进行培训可以改善许多感知任务,例如图像分类,对象检测和半分割。我们是第一个探索生成数据增强的人。我们提出了Scribblegen,这是一种生成数据增强方法,该方法利用ControlNET扩散模型,该模型以语义涂鸦为条件,以产生高质量的训练数据。但是,生成数据增强的幼稚实施可能会无意中损害下游分段的性能,而不是改善它。我们利用无分类器扩散指南来执行类的一致性,并引入编码ratios来将数据多样性换成数据现实主义。使用指导量表和编码比率,我们可以生成一系列高质量训练图像。我们提出了多个增强方案,发现这些方案显着影响模型性能,尤其是在低数据制度中。我们的框架进一步减少了涂鸦监督段的性能和完全监督的分割之间的差距。我们还表明,我们的框架显着改善了小数据集上的细分性能,甚至超过了完全监督的细分。该代码可在https://github.com/mengtang-lab/scribblegen上找到。

肿瘤成像中的生成AI
肿瘤成像的景观正在经历地震转变,这是由于生成人工智能(AI)的快速进步所推动的。这种变革性技术不仅增强了我们检测和诊断癌症的能力。它重新定义了肿瘤学护理的整个范式。当我们站在这场革命的风口浪尖上时,重要的是要研究生成AI在癌症成像中的深远影响,并探索其重塑肿瘤学未来的潜力。生成的AI方法是众所周知的,这要归功于Chatgpt及其许多竞争对手。但是生成的AI技术,例如生成对抗网络(GAN)和脱氧扩散概率模型(DDPM),也证明了在医学成像中的显着功能[1,2]。这些模型可以生成合成的医学图像,增强图像质量,甚至可以预测肿瘤的未来发展。在肿瘤学成像中,这转化为早期检测,更准确的诊断和改进的治疗计划。生成AI的最有希望的应用之一是应对医学成像中数据稀缺性的多年生挑战。癌症,尤其是在早期阶段,常常会出现很容易错过的微妙异常。通过产生稀有癌症类型或早期肿瘤的合成图像,AI可以显着扩展可用于培训诊断算法的数据集。
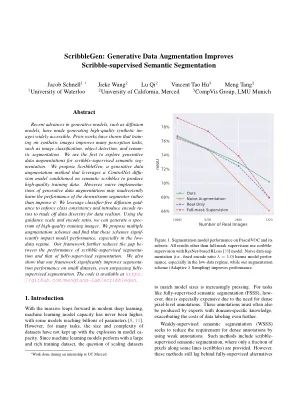
生成数据增强改善涂鸦 -
生成模型(例如扩散模型)的最新进展使生成高质量的合成IMEGES可以广泛访问。先前的工作表明,对合成图像进行培训可以改善许多感知任务,例如图像分类,对象检测和半分割。我们是第一个探索涂鸦审议语义序列的生成数据增强。我们提出了Scribblegen,这是一种生成数据增强方法,该方法利用ControlNET扩散模型,该模型以语义涂鸦为条件,以产生高质量的训练数据。但是,生成数据增强的幼稚实施可能会无意中损害下游分段的性能,而不是改善它。我们利用无分类的扩散指南来执行类的一致性,并引入编码ratios来将数据多样性换成数据现实主义。使用指导量表和编码比率,我们可以生成一系列高质量训练图像。我们提出了多个增强方案,并发现这些方案显着影响模型性能,尤其是在低数据状态下。我们的框架进一步减少了涂鸦监督段的性能和完全监督的分割之间的差距。我们还表明,我们的框架显着提高了小数据集上的细分性能,甚至超过了完全监督的细分。该代码可在https://github.com/mengtang-lab/scribblegen上找到。
![arXiv:2304.04106v1 [ed.IV] 4 月 8 日](/simg/c\c976a17a8c8510b56eac023ef34fc18fe9ddd97f.webp)
arXiv:2304.04106v1 [ed.IV] 4 月 8 日
摘要。获取和注释足够的标记数据对于开发准确且稳健的基于学习的模型至关重要,但在许多医学图像分割任务中,获取此类数据可能具有挑战性。一种有希望的解决方案是将真实数据与地面实况掩模注释合成。然而,之前没有研究探索过使用掩模生成完整的 3D 体积图像。在本文中,我们提出了 MedGen3D,这是一个可以生成成对的 3D 医学图像和掩模的深度生成框架。首先,我们将 3D 医学数据表示为 2D 序列,并提出多条件扩散概率模型 (MC-DPM) 来生成遵循解剖几何的多标签掩模序列。然后,我们使用以生成的掩模序列为条件的图像序列生成器和语义扩散细化器来生成与生成的掩模对齐的逼真的 3D 医学图像。我们提出的框架保证了合成图像和分割图之间的准确对齐。在 3D 胸部 CT 和脑部 MRI 数据集上进行的实验表明,我们的合成数据既丰富又忠实于原始数据,并展示了对下游分割任务的好处。我们预计,MedGen3D 合成配对 3D 医学图像和掩模的能力将在训练用于医学成像任务的深度学习模型方面发挥重要作用。

评估使用扩散降解概率模型
生成的AI模型,例如稳定的扩散,DALL-E和MIDJOURNEY,最近引起了广泛的关注,因为它们可以通过学习复杂,高维图像数据的分布来产生高质量的合成图像。这些模型现在正在适用于医学和神经影像学数据,其中基于AI的任务(例如诊断分类和预测性建模)通常使用深度学习方法,例如卷积神经网络(CNNS)和视觉变形金刚(VITS)(VITS),并具有可解释性的增强性。在我们的研究中,我们训练了潜在扩散模型(LDM)和deno的扩散概率模型(DDPM),专门生成合成扩散张量张量成像(DTI)地图。我们开发了通过对实际3D DTI扫描进行训练以及使用最大平均差异(MMD)和多规模结构相似性指数(MS-SSSIM)评估合成数据的现实主义和多样性来生成平均扩散率的合成DTI图。我们还通过培训真实和合成DTI的组合来评估基于3D CNN的性别分类器的性能,以检查在培训期间添加合成扫描时的性能是否有所提高,作为数据增强形式。我们的方法有效地产生了现实和多样化的合成数据,有助于为神经科学研究和临床诊断创建可解释的AI驱动图。

对不断发展的威胁景观中深层图像检测的最新进展的分析
摘要 - 使用深层生成模型生成的深层效果或合成图像对在线平台构成了严重的风险。这触发了几项研究工作,以准确检测DeepFake图像,在公开可用的DeepFake数据集上取得了出色的性能。在这项工作中,我们研究了8个州的探测器,并认为由于最近的两个发展,他们还远未准备好部署。首先,轻巧的方法的出现可以自定义大型生成模型,可以使攻击者能够创建许多自定义的发电机(创建深层效果),从而实质上增加了威胁表面。我们表明,现有的防御能力无法很好地推广到当今公开可用的用户定制的生成模型。我们讨论了基于内容不足的功能的新机器学习方法,并进行集成建模,以提高对用户定制模型的概括性能。第二,视觉基础模型的出现 - 经过广泛数据训练的机器学习模型,可以轻松地适应几个下游任务 - 攻击者可能会滥用攻击者来制作可以逃避现有防御措施的对抗性深击。我们提出了一次简单的对抗性攻击,该攻击通过仔细的语义操纵图像内容来利用现有的基础模型在不增加任何对抗性噪声的情况下制作对抗性样本。我们强调了针对我们的攻击的多种防御能力的脆弱性,并探索了利用高级基金会模型和对抗性训练来防御这种新威胁的方向。

国际当前科学研究与评论杂志
Santosh Kumar Hcltech,美国公司,摘要:小儿肺炎是全球发病率和死亡率的主要原因,需要准确及时诊断。 本研究探讨了使用胸部X光片对生成AI的应用对小儿肺炎进行分类。 利用深度学习技术,包括生成对抗网络(GAN)和变异自动编码器(VAE),我们增强了图像质量,生成合成训练数据并提高模型的通用性。 所提出的框架集成了AI驱动的特征提取,卷积神经网络(CNN)和注意机制,以提高诊断精度。 与传统方法相比,结果表现出分类性能的显着改善,重点是解释性和临床可用性。 关键字:生成AI,小儿肺炎,胸部X光片,卷积神经网络(CNN),生成对抗网络(GAN),数据增强,医学图像分类,肺炎诊断,深度学习,合成数据。 引言肺炎仍然是全球儿童死亡率的主要原因,并且必须通过胸部X光片进行准确的诊断。 但是,放射线解释的可变性和对专家放射科医生的访问有限的挑战。 生成的AI通过生成高质量的合成图像来提供一种变革性的方法,以用于模型训练和增强图像清晰度。 本研究研究了AI在肺炎分类中的作用,解决数据稀缺,改善模型概括并降低误诊率。Santosh Kumar Hcltech,美国公司,摘要:小儿肺炎是全球发病率和死亡率的主要原因,需要准确及时诊断。本研究探讨了使用胸部X光片对生成AI的应用对小儿肺炎进行分类。利用深度学习技术,包括生成对抗网络(GAN)和变异自动编码器(VAE),我们增强了图像质量,生成合成训练数据并提高模型的通用性。所提出的框架集成了AI驱动的特征提取,卷积神经网络(CNN)和注意机制,以提高诊断精度。与传统方法相比,结果表现出分类性能的显着改善,重点是解释性和临床可用性。关键字:生成AI,小儿肺炎,胸部X光片,卷积神经网络(CNN),生成对抗网络(GAN),数据增强,医学图像分类,肺炎诊断,深度学习,合成数据。引言肺炎仍然是全球儿童死亡率的主要原因,并且必须通过胸部X光片进行准确的诊断。但是,放射线解释的可变性和对专家放射科医生的访问有限的挑战。生成的AI通过生成高质量的合成图像来提供一种变革性的方法,以用于模型训练和增强图像清晰度。本研究研究了AI在肺炎分类中的作用,解决数据稀缺,改善模型概括并降低误诊率。生成模型与深度学习分类器的整合确保了小儿肺炎检测的稳健性和可靠性。方法论,本研究采用了混合AI框架,该框架结合了生成的对抗网络(GAN)和变异自动编码器(VAE),以进行数据增强,然后进行卷积神经网络(CNN)和基于变压器的分类器进行肺炎分类。