
机构名称:
¥ 1.0
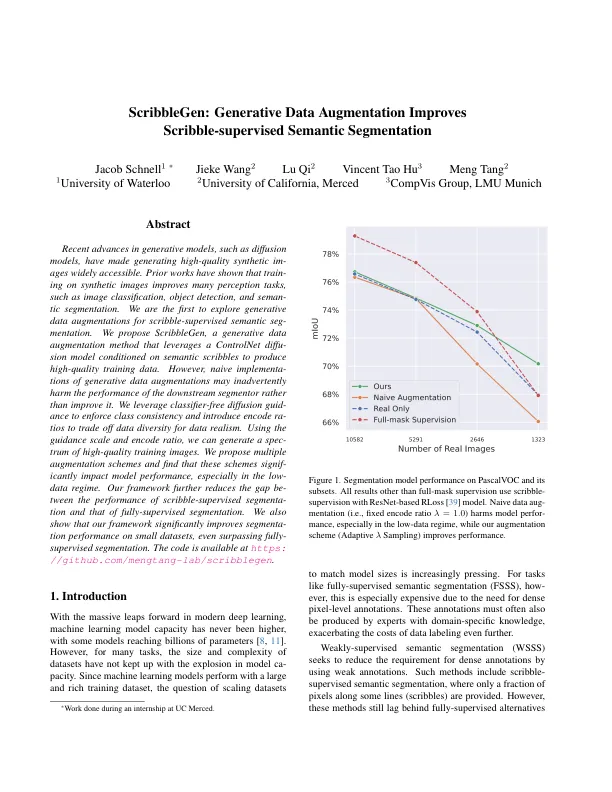
生成模型(例如扩散模型)的最新进展使生成高质量的合成IMEGES可以广泛访问。先前的工作表明,对合成图像进行培训可以改善许多感知任务,例如图像分类,对象检测和半分割。我们是第一个探索涂鸦审议语义序列的生成数据增强。我们提出了Scribblegen,这是一种生成数据增强方法,该方法利用ControlNET扩散模型,该模型以语义涂鸦为条件,以产生高质量的训练数据。但是,生成数据增强的幼稚实施可能会无意中损害下游分段的性能,而不是改善它。我们利用无分类的扩散指南来执行类的一致性,并引入编码ratios来将数据多样性换成数据现实主义。使用指导量表和编码比率,我们可以生成一系列高质量训练图像。我们提出了多个增强方案,并发现这些方案显着影响模型性能,尤其是在低数据状态下。我们的框架进一步减少了涂鸦监督段的性能和完全监督的分割之间的差距。我们还表明,我们的框架显着提高了小数据集上的细分性能,甚至超过了完全监督的细分。该代码可在https://github.com/mengtang-lab/scribblegen上找到。
生成数据增强改善涂鸦 -
主要关键词




相关文件推荐





























