XiaoMi-AI文件搜索系统
World File Search System子类

使用机器的金融交易中的欺诈检测...
I.简介欺诈性销售和传感器长期以来已经交织在一起。在互联网的现代时代,欺诈性交易比以往任何时候都更频繁,这是财务损失的主要来源。销售欺诈带来的节俭金额在2019年超过280亿美元,2020年的300亿美元,到2021年的320亿美元。全球预计销售欺诈将继续攀升,在2022年达到340亿美元。因此,为了庆祝和筛选财政交易,银行和财政服务提供商可能需要一个自动欺诈的查找工具。欺诈检测工具旨在确定大量交易数据中的异常行为模式,然后利用这些模式来分析和监视新的商机(2,3)。机器素养是一种人工智能(AI)功能系统的改进和素养(1-10)。为了根据我们提供的示例来找到数据中的模式,并根据我们提供的示例形成更好的判断,扫盲过程始于合规或数据,这与示例,第一手的经验或指导相当(11-20)。主要目标是使计算机在没有人为援助的情况下自行学习,或者在后果(21-30)中对适应性行为的支持。具有无监督学习能力的网络称为“深层扫盲”,这是“机器素养”的子类

全局淬灭后三部分信息的普适性
我们考虑无限量子自旋链中连通子系统 A ∪ B ∪ C 的宏观大 3-划分 ( A, B, C ),并研究 R´yi- α 三部分信息 I ( α ) 3 ( A, B, C )。在具有局部哈密顿量的干净一维系统中,在平衡态下它通常为零。一个值得注意的例外是共形临界系统的基态,其中 I ( α ) 3 ( A, B, C ) 是交比 x = | A || C | / [( | A | + | B | )( | C | + | B | )] 的普适函数,其中 | A | 表示 A 的长度。我们确定了不同类的状态,这些状态在具有平移不变哈密顿量的时间演化下,局部放松到具有非零(R´enyi)三部分信息的状态,此外还表现出对 x 的普适依赖性。我们报告了对自由费米子对偶系统中 I ( α ) 3 的数值研究,提出了场论描述,并计算了它们在一般情况下对 α = 2 的渐近行为以及在系统子类中对一般 α 的渐近行为。这使我们能够推断出缩放极限 x → 1 − 中的 I ( α ) 3 的值,我们称之为“残差三部分信息”。如果非零,我们的分析指向一个与 R´enyi 指数 α 无关的通用残差值 − log 2,因此也适用于真正的(冯·诺依曼)三部分信息。

区域选择性光氧化还原催化环加成反应...
非环状羰基叶立德与偶极亲和剂的选择性 [3+2] 偶极环加成反应是一种非常有用的方法,可以合成具有复杂饱和度和取代基变化的五元氧杂环。1 此类环醚(四氢、二氢和呋喃)是许多生物活性天然产物和药物中发现的重要结构基序。2 不幸的是,虽然 [3+2] 环加成仍然是上述产品的可行方法,但 1,3- 偶极羰基叶立德在化学界尚未得到充分利用,原因是催化剂昂贵或无法在温和条件下有效生成叶立德中间体。3 为了解决这些缺点,我们的小组开发了一种有机光氧化还原方案,从二芳基环氧物生成羰基叶立德,该方案在与偶极亲和剂环化后产生环醚。然后将这些环醚用于经典的木脂素天然产物全合成(方案 1)。4 虽然我们的方法范围广泛,并有效地为该木脂素天然产物子类提供了统一的方法,但通过这种方法在环加成过程中实现区域选择性尚未实现。

航空应用用户群
混合架构称为地面区域增强系统 (GRAS)。基于飞机的方法采用内置于用户航空电子设备中的监视器,不需要外部基础设施(GNSS 卫星本身除外)。这些监视器通过检测危险误导信息 (HMI) 实例(指任何威胁性 GNSS 异常)来构建严格的误差界限。与基于飞机的方法相比,其他类型的增强系统都采用地面参考接收器基础设施。这些接收器网络增强了 HMI 监控的灵敏度。此外,这些网络能够广播差异校正,从而显着提高用户准确性。图 1 显示了所有四类增强系统。ABAS 具有明显的优势,因为它几乎可以在任何可以看到 GNSS 卫星的地方使用。虽然 ABAS 可能包含非 GNSS 传感器,但 ABAS 的一个重要子类别是仅 GNSS 的 RAIM。这种方法使用导航解决方案的最小二乘残差来实现监控。较大的残差对应于与其他测量值不同的测量值。通过从导航解决方案中排除不同的卫星测量值,RAIM 可以检测到较大的 HMI 事件,从而可以对导航传感器误差建立更严格的置信界限。为了获得非零残差,RAIM 至少需要一次
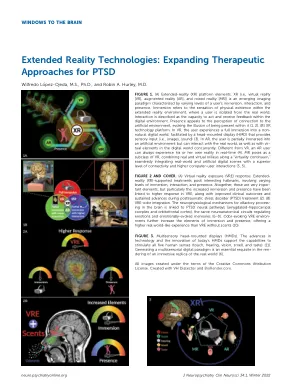
扩展PTSD的治疗方法
图1。(a)扩展现实(XR)平台元素。Xr(即虚拟现实[VR],增强现实[AR]和混合现实[MR])是一种新兴的成像范式,其特征是用户的沉浸,交互和存在的不同级别。浸入是指扩展现实环境中物理存在的感觉,在扩展现实环境中,用户与现实世界隔离开来。互动被描述为在数字环境中采取行动和接收反馈的能力。存在吸引了人们对人工环境的联系的感知,引起了其中存在的幻想(1、2)。(b)XR技术平台。在VR中,用户完全沉浸在非自然数字世界中,这是由头部安装显示(HMD)促进的,该显示器提供了感官输入(即图像,声音)(3)。在AR中,用户部分沉浸在人工环境中,但可以与现实世界以及数字世界中的元素互动。与VR不同,AR用户总是可以实时体验他或她自己的现实(4)。MR姿势是VR的子类,将真实和虚拟环境结合在“虚拟连续性”中,无缝地将现实世界和人工数字场景与较高的连接性和较高的计算机用户相互作用级别相结合(3,5)。

使用多模式放射学的神经胶质瘤分类... -orca
摘要。神经胶质瘤是脑肿瘤,死亡率高。该肿瘤有各种等级和子类型,并且治疗过程相应地变化。临床医生和肿瘤学家根据视觉检查放射学和组织学数据来诊断并诊断这些肿瘤。但是,此过程可能是耗时且主观的。计算机辅助方法可以帮助临床医生做出更好,更快的决定。在本文中,我们提出了使用放射学和组织病理学图像同时,提出了将神经胶质瘤自动分类为三种亚类型的管道。所提出的方法实现了用于放射性和组织学模式的不同分类模型,并通过结合方法将它们结合在一起。分类算法最初通过深度学习方法执行瓷砖级(用于组织学)和切片级别(用于放射学)进行分类,然后将瓷砖/切片级的潜在特征合并为全幻灯片和全磁盘子和全磁性子类别的预测。使用CPM-RadPath 2020挑战中提供的数据集评估了分类算法。提议的管道达到了0.886的F1得分,共同的KAPPA得分为0.811,平衡精度为0.860。所提出的模型对各种特征的端到端学习的能力使其能够对神经胶质瘤肿瘤亚型的可比预测。

文章
用白光发射二极管(WLEDS)更换传统的白炽灯,卤素和荧光灯,预计到2030年将使全球用电量减少三分之一。当前的WLED技术使用基于稀土元素(REE)的磷光材料,这不仅是成本密集的,而且构成了环境问题。因此,研究人员正在寻求新一代的光电材料,这些材料可以取代WLED中的常规磷酸盐,因此旨在为未来提供更清洁,更节能的照明技术。发光的金属有机框架(LMOF)最近成为一种新的MOF子类,它们在感应,成像,光电,光电子化和固态照明(SSL)技术方面具有巨大的应用潜力。lmof可以是游戏改变者,因为诸如高发光量子产率,可调式激发和排放等优点,可以通过合理的设计和金属中心,接头分子的优化,宾客分子的优化,设备易于制造以及结构鲁棒性来哄骗。LMOF的这些明确的优势特征使它们在其他当代材料上得分,并使它们为WLED技术提供了未来派的磷光材料。在本功能文章中,我们将概述基于LMOF的SSL的最新发展,以特别关注WLED技术。重点将集中在无REE的LMOF上,因为目的是将读者的注意力引导到更可行,更绿色的照明技术。

人类杂交瘤狼疮抗凝剂区分层状和六角形相脂质系统”
磷脂抗体可能具有重要的生理和生物学功能。狼疮抗凝物代表抗磷脂抗体的一个子类,其特点是能够延长体外凝血试验中部分凝血活酶时间 (PTT) 的凝血时间 (Thiagarajan, P.、Shapiro, SS 和 DeMarco, L. (1980) J. Clin. Inveet. 66, 397-405)。在本研究中,我们通过将 13 名系统性红斑狼疮患者的淋巴细胞与 GM 4672 淋巴母细胞系融合来产生杂交瘤。在得到的 67 种杂交瘤自身抗体中,发现 14 种 (21%) 延长了改良的 PTT 测定,并对其中 11 种抗体进行了进一步分析。使用改良的 PTT 检测法进行的竞争实验表明,六角相磷脂(包括天然和合成形式的磷脂酰乙醇胺)能够中和所有 11 种杂交瘤抗体的狼疮抗凝活性。相反,层状磷脂(如磷脂酰胆碱和合成层状形式的磷脂酰乙醇胺)对抗凝活性没有影响。因此,这些抗体能够根据纯结构标准识别磷脂。抗磷脂抗体能够区分磷脂的不同结构排列,这一证明可能对自身免疫的免疫调节具有重要意义。

小脑和神经发育障碍
小脑发育缺陷越来越多地被认为是神经发育障碍 (NDD) 的风险因素,例如注意力缺陷多动障碍 (ADHD)、自闭症谱系障碍 (ASD) 和精神分裂症。自闭症患者的小脑异常以及人类患者中发现的一系列基因突变都影响小脑回路,特别是浦肯野细胞,并与运动功能、学习和社交行为缺陷有关;这些特征通常与自闭症和精神分裂症有关。然而,NDD(例如 ASD 和精神分裂症)还包括系统性异常,例如慢性炎症、异常昼夜节律等,这些无法通过仅影响小脑的病变来解释。在这里,我们汇集了支持小脑功能障碍在 NDD 中的作用的表型、回路和结构证据,并提出转录因子类视黄酸相关孤儿受体 α (ROR α) 提供了在 NDD 中观察到的小脑和系统异常所缺失的环节。我们介绍了 ROR α 在小脑发育中的作用,以及由于 ROR α 缺乏而发生的异常如何解释 NDD 症状。然后,我们重点关注 ROR α 如何与 NDD(特别是 ASD 和精神分裂症)相关联,以及其多种脑外作用如何解释这些疾病的全身成分。最后,我们讨论了 ROR α 缺乏如何通过诱发小脑发育缺陷(进而影响下游靶点)以及其对炎症、昼夜节律和性别二态性等脑外系统的调节,成为 NDD 的驱动力。

使用R软件的机器学习的财务应用
机器学习(ML)是人工智能(AI)的应用,它允许系统从经验中学习和改进而无需明确编程。在效果中,它是关于开发可以访问数据并自行学习的预测模型。有几种类型的学习,我们区分:监督学习:是使用真理完成的,也就是说,我们对样本的输出值应该是什么。因此,此类学习的目标是学习一个给定数据示例和所需结果的函数,以便最好地近似可观察到的输入和输出之间的关系。有两种类型的监督学习。分类算法试图预测试图预测连续价值的类别/类别和回归算法。无监督的学习:旨在进行数据结构推理。无监督学习中的两个最常见的子类别是聚类和降低性。在聚类观测中以一种产生较高的组内模拟和低组间相似性的方法进行了分组。已提出的聚类方法的不同类型是基于熵的,基于密度和基于分布的方法。降低维度旨在通过降低其维度,同时保留大多数固有信息来增加数据的信息密度。基于主成分分析(PCA)有不同的技术,该技术得出了原始变量的线性组合,以涵盖数据中尽可能多的差异。第二,基于神经网络的方法通过特定的体系结构降低了维度。