XiaoMi-AI文件搜索系统
World File Search System解释性

端到端对象检测的内在解释性
抽象的深度学习模型正在自动执行许多日常任务,表明将来,即使是高风险的任务也将是自动化的,例如医疗保健和自动化驱动区。但是,由于这种深度学习模型的复杂性,了解其推理是一项挑战。此外,设计的深度学习模型的黑匣子性质可能会破坏公众对关键领域的信心。当前对本质上可解释的模型的努力仅着眼于分类任务,而在对象检测中留下了差距。因此,本文提出了一个深度学习模型,该模型可用于对象检测任务。这种模型所选的设计是众所周知的快速RCNN模型与ProtopNet模型的组合。对于可解释的AI实验,所选的性能度量是Protopnet模型的相似性评分。我们的实验表明,这种组合导致了一个深度学习模型,该模型能够以相似性得分来解释其分类,并使用视觉上的“单词袋”(称为原型)在训练过程中学习。此外,采用这种可解释的方法似乎并没有阻碍提出的模型的性能,该模型在Kitti数据集中获得了69%的地图,而GrazpedWri-DX数据集则获得了66%的地图。此外,我们的解释对相似性得分的可靠性很高。

FAIRX:使用公平,实用性和解释性
摘要我们提出了Fairx,这是一种基于python的开源基准测试工具,旨在全面分析公平,效用和解释性(XAI)的模型。FAIRX使用户可以使用各种公平指标,数据实用程序指标来训练基准测试模型,并评估其公平性,并在统一框架内生成模型预测的解释。现有的基准测试工具无法评估从公平生成模型产生的合成数据,也不支持培训公平生成模型。在Fairx中,我们在收集我们的Fair-Model库(预处理,处理,后处理)和评估指标中添加了公平生成模型,以评估合成公平数据的质量。此版本的FaiRX支持表格数据集和图像数据集。它还允许用户提供自己的自定义数据集。开源Fairx基准测试包在https://github.com/fahim-sikder/fairx上公开可用。

钻井操作安全案例:解释性指南
•简介概述了文件的范围和目的,涵盖安全案件的设施,批准和托管详细信息的立法,主要标准和实践守则,有关安全案件和其他行政要求的通信的地址(第3.1节)。•操作说明提供了该设施,其功能和控制系统的简洁概述(第3.2节)。•安全管理系统(SMS)提供了对维护设施和工人安全的管理系统的详细说明。这包括安全性关键要素(SCE)的绩效标准,并支持正式安全评估(FSA)的发现(第3.3节)。•正式的安全评估提供了对设施的风险管理方法的详细说明,风险评估咨询的摘要,已确定的重大事故事件的详细信息(MAES),降低风险SFAIRP和BOWTIE图表(第3.4节)。•紧急响应计划提供了设施的ERP的详细说明,包括ERP符合WHS Pageo法规的证据(第3.5节)

定义机器人解释和可解释性引擎
摘要 - 在一个自主机器人越来越居住在公共场所中的时代,其决策过程中透明度和解释性的必要性变得至关重要。本文介绍了机器人解释和解释性引擎(Roxie)的概述,该引擎构成了这种批判性需求,旨在揭示复杂机器人行为的不透明性质。本文阐明了提供有关机器人决策过程的信息和说明所需的关键功能和要求。它还概述了可与ROS 2部署的软件组件和库的套件,使用户能够对机器人过程和行为提供全面的解释和解释,从而促进了人类机器人互动中的信任和协作。
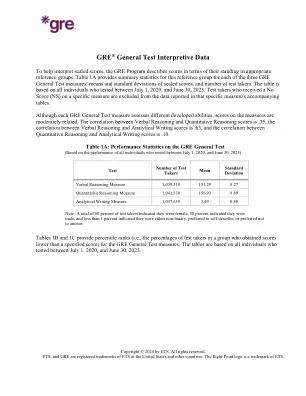
GRE®通用测试解释性数据
gre®通用测试解释性数据有助于解释缩放分数,GRE计划以其在适当的参考组中的地位描述了分数。表1a为此参考组提供了三种GRE一般测试措施中的每个参考组的摘要统计信息:缩放分数的均值和标准偏差和测试者的数量。表是基于所有在2020年7月1日至2023年6月30日之间进行测试的个人。在特定措施随附的表中报告的数据中排除了在特定措施上获得无分数(NS)的测试接受者。尽管每种GRE一般测试措施都评估了不同的发达能力,但措施的分数适中相关。言语推理与定量推理得分之间的相关性为.35,言语推理与分析写作评分之间的相关性为.63,定量推理与分析写作分数之间的相关性为.10。

从事后解释性到自我解释模型
[1]辛西娅·鲁丁(Cynthia Rudin)。停止解释用于高赌注决策的黑匣子机器学习模型,然后使用可解释的模型。自然机器智能,1(5):206–215,2019 [2]MarcoTúlioRibeiro,Sameer Singh和Carlos Guestrin。“我为什么要信任您?”:解释任何分类器的预测。Corr,ABS/1602.04938,2016。[3] Sebastian Bach,Alexander Binder,GrégoireMontavon,Frederick Klauschen,Klaus-RobertMüller和Wojciech Samek。通过层次相关性传播对非线性分类器决策的像素智慧解释。plos One,10(7):1-46,07 2015。[4] Alina Barnett,Jonathan SU,Cynthia Rudin,Chaofan Chen,Oscar Li。这看起来像:深入学习可解释的图像识别。在神经信息处理系统会议论文集(Neurips),2019年。

罗杰斯先生提交的解释性声明
*2012 财年,陆军现役部队最终兵力包括 14,600 名士兵的临时最终兵力; *2013 财年,陆军现役部队最终兵力包括海外应急行动预算中要求的 49,700 名陆军最终兵力,以及陆军临时最终兵力陆军医疗(TEAM)计划基本预算中要求的 12,400 名增加兵力,该计划与综合可部署性评估系统中的非部署士兵有关; -2013 财年,海军陆战队现役部队最终兵力包括海外应急行动预算中要求的 15,200 名海军陆战队最终兵力

灵活且针对具体情境的 AI 可解释性
摘要 近年来人们对人工智能 (AI) 的热情主要归功于深度学习的进步。深度学习方法非常准确,但也不太透明,这限制了它们在安全关键型应用中的潜在应用。为了获得信任和问责,机器学习算法的设计者和操作者必须能够向用户、监管者和公民解释算法的内部工作原理、结果以及失败的原因。本文的独创性在于结合可解释性的技术、法律和经济方面,开发一个框架来定义给定环境下可解释性的“正确”水平。我们提出了三个逻辑步骤:首先,定义主要的背景因素,例如解释的受众是谁、操作背景、系统可能造成的危害程度以及法律/监管框架。此步骤将有助于描述解释的操作和法律需求,以及相应的社会效益。第二步,检查可用的技术工具,包括事后方法(输入扰动、显著性图……)和混合 AI 方法。第三步,根据前两个步骤,选择正确的全局和局部解释输出级别,同时考虑所涉及的成本。我们确定了七种成本,并强调只有当总社会效益超过成本时,解释才具有社会意义。

亚马逊人工智能公平性和可解释性白皮书
开发负责任的 AI 解决方案是一个过程,涉及在 ML 生命周期的所有阶段与关键利益相关者(包括产品、政策、法律、工程和 AI/ML 团队以及最终用户和社区)的意见和讨论。在本文中,我们主要关注 ML 生命周期中用于解决偏见和可解释性的技术工具。我们还提供了一个简短的部分,介绍了使用 AI 实现公平性和可解释性的局限性和最佳实践。

附有解释性声明的护士道德规范
道德是护理基础不可或缺的一部分。护理在关注病人、受伤者和弱势群体的福祉以及社会正义方面有着悠久的历史。这种关注体现在为个人和社区提供护理服务中。护理包括预防疾病、减轻痛苦以及在照顾个人、家庭、团体和社区时保护、促进和恢复健康。护士采取行动来改变那些有损健康和福祉的社会结构方面。成为护士的个人不仅要遵守职业的理想和道德规范,还要将其作为护士工作的一部分。护理的道德传统是自我反思、持久和独特的。道德准则明确了该职业的主要目标、价值观和义务。