XiaoMi-AI文件搜索系统
World File Search System适应控制

基于NSUC1610的车载步进电机控制
NSUC1610 是通过反电动势的大小来进行堵转检测,在马达相位未通电期间,可以检测到 BEMF 电压。但这 不包括全步进模式,因为两个相位始终通电。以下假设在微步进模式下检测失速,BEMF 电压与电机转速成 正比,这样可以判断电机是否运行。由于只有在一相未通电的情况下才能进行测量,因此对 BEMF 电压的观 察非常有限。对于理想的电机,在没有任何负载和损耗的情况下,转子将随着定子磁场持续旋转,并且在相电 流为零时,可以看到 BEMF 电压的峰值。对于实际电机和外加负载,转子将始终滞后于定子磁场。此负载相关 相位滞后将导致固定测量点处 BEMF 电压的负载相关变化。在零相位滞后的情况下,可以测量 BEMF 电压峰 值,并且只能看到反电势与速度的相关性。在与负载变化的情况下,反电势会产生相位滞后,BEMF 电压将从 峰值将出现偏移,当这个电压大于或者小于一个阈值时,这就标志着检测到失步点,电机运动将停止。BEMF 电压测量仅在零电流阶跃期间启用。在零电流阶跃结束时,采样和测量最后一次 BEMF 电压值。这可确保线 圈电流达到零,且 BEMF 电压实际可见。根据电机参数、速度和阶跃模式,零阶跃可能会变短,并且无法获得 明显的 BEMF 电压。此时则无法检测失速。失速检测仅在匀速运动期间进行,在加速或减速期间,BEMF 电压 可能非常低,则不会启用失速检测。具体电流波形如图 2.5 所示:
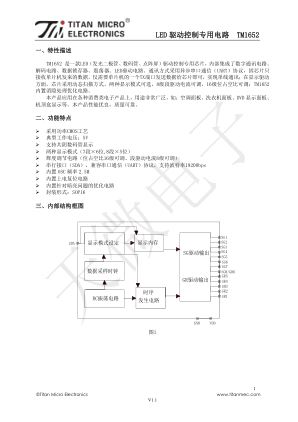
LED 驱动控制专用电路TM1652
Command1~Command n: 发送显示地址命令,地址1~n(最多可设置6个地址) Data1~Data n:发送显示数据(最多6 bytes) Time:数据线置高时间(最小时间为3ms) CommandX:发送显示控制命令(0x18) CommandY:发送显示控制调节命令(包括位占空比、段驱动电流以及显示模式设置) 芯片不需要命令来设置芯片是工作在地址自动加1模式还是固定地址模式,严格来说它只有一种地 址自动加1模式,此处划分是为了更好地说明芯片也可以单独给某个显示寄存器地址写显示数据,如 果单独给某个显示地址写显示数据,写完显示地址后,紧跟着只能写一个显示数据,就把信号线置高 至少3ms,如果紧跟着写几个显示数据,那么芯片在接收到第一个数据后,显示地址就会在规定的地 址上自动加1,再接收第二个显示数据,直到接收到最后一个显示地址的显示数据。
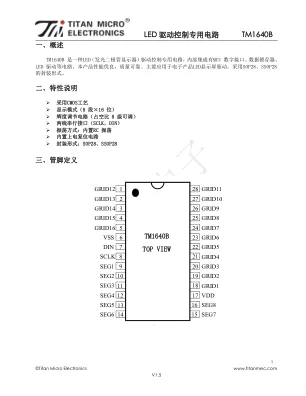
LED 驱动控制专用电路TM1640B
0 0 0 0 00H 1 1 0 0 0 1 01H 1 1 0 0 1 0 02H 1 1 0 0 1 1 03H 1 1 0 1 0 0 04H 1 1 0 1 0 1 05H 1 1 0 1 1 0 06H 1 1 0 1 1 1 07H 1 1 1 0 0 08H 1 1 1 0 0 1 09H 1 1 1 0 1 0 0AH 1 1 1 0 1 1 0BH 1 1 1 1 0 0 0CH 1 1 1 1 0 1 0DH 1 1 1 1 1 0 0EH 1 1 1 1 1 0FH

电子与控制工程学院 School of Electronoics and Control ...
研究小组专注于模式识别,计算机视觉,信号处理和机器学习(深度学习)方法。我们的重点在于探索国际科学和技术最前沿,以建立智能图像解释(多模式遥感信息获取和处理),时空的大数据分析和处理,边缘计算(嵌入人工智能)以及其他相关领域的专业知识。
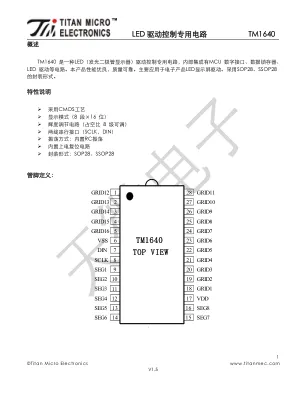
LED 驱动控制专用电路TM1640
微处理器的数据通过两线总线接口和TM1640 通信,在输入数据时当CLK 是高电平时,DIN 上的信号必须 保持不变;只有CLK 上的时钟信号为低电平时,DIN 上的信号才能改变。数据的输入总是低位在前,高位在后 传输.数据输入的开始条件是CLK 为高电平时,DIN 由高变低;结束条件是CLK 为高时,DIN 由低电平变为高 电平。
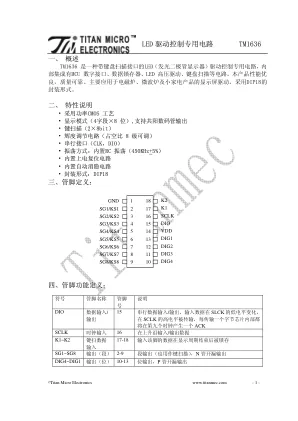
LED 驱动控制专用电路TM1636
在有按键按下时,读键数据如下: SG1 SG2 SG3 SG4 SG5 SG6 SG7 SG8 K1 1110_1111 0110_1111 1010_1111 0010_1111 1100_1111 0100_1111 1000_1111 0000_1111 K2 1111_0111 0111_0111 1011_0111 0011_0111 1101_0111 0101_0111 1001_0111 0001_0111 在无按键按下时,读键数据为: 1111_1111 ; 七、 接口说明 微处理器的数据通过两线总线接口和 TM1636 通信,在输入数据时当 SCLK 是高电 平时, DIO 上的信号必须保持不变;只有 SCLK 上的时钟信号为低电平时, DIO 上的信号 才能改变。数据输入的开始条件是 SCLK 为高电平时, DIO 由高变低;结束条件是 SCLK 为高时, DIO 由低电平变为高电平。 TM1636 的数据传输带有应答信号 ACK ,在传输数据的过程中,在时钟线的第九个 时钟芯片内部会产生一个应答信号 ACK 将 DIO 管脚拉低。 指令数据传输过程如下图(读按键数据时序):

LED 驱动控制专用电路TM1637
符号 单位: 毫米 最小值 典型值 最大值 A 3.71 4.00 4.31 A1 0.50 0.60 0.80 A2 3.20 3.40 3.60 B 0.33 0.45 0.53 B1 1.525(TYP) C 0.20 0.28 0.36 D 25.70 26.00 26.54 E 6.20 6.40 6.75 E1 7.32 7.78 8.25 e 2.54(TYP) L 3.00 3.30 3.60 E2 8.20 8.70 9.10 B2 0.87 1.02 1.17

LCD 驱动控制专用电路TM1723
Bit0 Bit1 Bit2 Bit3 Bit4 Bit5 Bit6 Bit7 位 图( 3 ) ▲注意: 1 、 TM1723 最多可以读 2 个字节,不允许多读。 2 、读数据字节只能按顺序从 BYTE1-BYTE2 读取,不可跨字节读。例如:硬件上的 KEY2 与 KS3 对应按键按下时, 此时想要读到此按键数据,必须需要读到第 2 个字节的第 6BIT 位,才可读出数据;当 KEY1 与 KS3 , KEY2 与 KS3 , KEY3 与 KS3 三 个按键同时按下时,此时 BYTE2 所读数据的 B5 , B6 , B7 位均为 1 。 3 、组合键只能是同一个 KS ,不同的 KEY 引脚才能做组合键;同一个 KEY 与不同的 KS 引脚不可以做成组合键使用。 7.3.按键扫描


基于四元数和动态逆的无人机精确航迹控制
知识共享署名许可协议( http : / / creativecommons.org / licenses / by / 4.0 ),其中这是一篇开放获取的文章,根据知识共享署名许可协议( http : / / creativecommons.org /许可/ by/ 4.0 ),其中