XiaoMi-AI文件搜索系统
World File Search System音频数据

模型课程
Terminal Outcomes: ● Use selected AI applications online to explore various types of AI ● Recognize AI applications in everyday life ● Identify the various types of problems that AI can solve ● Breakdown a human action into parts to identify learning requirements and processes involved ● Identify the various components of human learning ● Identify the use of data in various given activities and applications ● Recognize different types of data and explore how the same data can be represented in different ways ● Analyze and从表示数据,符号和图表中提取信息●调查数字系统如何表示二进制中的文本,图像和音频数据●解释代数,概率和统计信息在AI中的作用●解释在AI中进行数据可视化的需求●AI●解决问题的问题解决方案的解决方案●warge a I Seption beartion weartion beartion beart pocution beartion beartion beartion beard pocution beard pocution warry pocution beartion beartion warry pocution●培训现有的AII●培训AI II II●培训AI II●使用Python语言

lipsound2:自我监督的嘴唇到语音重建和唇读的预训练
摘要 - 这项工作的目的是通过利用视频中音频和视觉流的自然共发生来研究跨模式自我监管的预训练对语音重新构造的影响。我们提出的LIPSOUND2由编码器 - 二次结构和位置意识到的注意机制组成,以将面部图像序列映射到MEL尺度频谱图,而无需任何人类注释。提出的LIPSOUND2模型是在〜2400-h多语言(例如英语和德语)音频数据(Voxceleb2)上首次预先训练。为了验证所提出的方法的普遍性,我们随后在域特异性数据集(网格和TCD-TIMIT)上进行了预训练的模型,以进行英语语音重建,并与依赖于讲话者依赖于依赖于讲话者的依赖于讲话者的言语质量和清晰度相比,对语音质量和清晰度的改善显着提高。除了英语外,我们还对中国普通话唇读(CMLR)数据集进行了中文语音重建,以验证对可转移性的影响。最后,我们通过在预先训练的语音识别系统上培养生成的音频并在英语和中文基准数据集上实现状态性能来训练级联的唇读(视频对文本)系统。

迈向多模态和用户友好型可解释人工智能的声音化
我们习惯于听取解释。例如,如果有人觉得你今天很伤心,他们可能会用“因为你太难过了”来回答你的“为什么?”。然而,今天的人工智能(AI)——如果有的话——主要是以视觉或文本的方式提供决策的解释。虽然这种方法适合通过视觉媒体进行交流,例如在研究论文或智能设备的屏幕中,但它们可能并不总是最好的解释方式;尤其是当最终用户不是专家时。特别是,当人工智能的任务是音频智能时,视觉解释似乎不如可听的、声音化的解释直观。声音化在处理非音频数据的系统中对可解释人工智能(XAI)也具有巨大潜力——例如,因为它不需要用户的视觉接触或主动注意。因此,人工智能决策的声音化解释面临着一项具有挑战性但极具前景和开创性的任务。这涉及结合创新的 XAI 算法,以便指向负责 AI 决策的学习数据,并包括数据分解以识别突出方面。它进一步旨在识别负责决策的预处理、特征表示和学习注意模式的组成部分。最后,它以模型级决策为目标,为决策链提供整体解释

办公自动化 - MIS ALU
现在,我们能够在几分钟内与世界上任何地方的任何人进行通信。互联网的电子邮件设施对社会大有裨益,尤其是在节省时间方面。计算机对许多方面产生了巨大影响,这一事实值得怀疑。它们构建了一个我们生活中难以获得的知识世界,并且提供了易于获取的信息。计算机需要软件来完成专门的任务。计算机系统中使用的软件分为应用软件、系统软件和实用软件。如今,我们在组织中使用计算机系统,借助特定软件的帮助来自动化工作。办公自动化是利用新技术改善工作环境的尝试。“办公自动化”一词是指应用于办公活动的所有工具和方法,这些工具和方法使得能够以计算机辅助方式处理书面、视觉和音频数据。它旨在提供简化、改进和自动化公司或群体活动组织(例如管理行政数据、同步会议等)的元素。沟通作为一种过程,与人类文明本身一样古老。不同文明的人们依赖不同的沟通方式,这取决于他们所处时代的科学技术进步水平。在计算机网络发明之前,我们称之为电信系统,计算机之间的通信

747 飞机环境研究设施 (AERF)
高级通用航空研究模拟器。这款固定式飞行模拟器专为研究应用而设计。它代表了 Piper Malibu/Matrix 级飞机(高性能、可伸缩起落架)。经过修改,它可以代替或与传统的圆形仪表一起提供可重新编程的电子飞行仪表,包括主飞行显示器、多功能显示器、平视显示器(插图)以及各种系统和/或导航显示器。它可以配置具有适当力负载的传统飞行控制装置或电传操纵侧臂性能控制系统。当采用玻璃座舱配置时,它代表了一种高性能、技术先进的飞机。它可以与其自己的 180 度窗外视觉系统(如图所示)一起使用,也可以与广角视觉系统一起使用。使用该设备的研究包括对飞行显示器(地形描绘合成视觉 PFD/HUD、补充地形显示器、NEXRAD 显示器、抬头和俯视飞行引导空中高速公路显示器、主姿态指示器和备用姿态指示器、附加或便携式导航显示器)的调查、飞行控制(常规和电传操纵性能控制)、故障期间的飞行员表现(自动驾驶仪、俯仰配平、ADI 部分面板故障、异常姿态恢复)和飞行员决策(使用天气显示器和/或信息来避免恶劣天气)的调查。数据收集功能包括飞行性能、视频和音频数据的数字捕获。
747 飞机环境研究设施(AERF)
先进通用航空研究模拟器。这种固定式飞行模拟器专为研究应用而设计。它代表了 Piper Malibu/Matrix 级飞机(高性能、可收放起落架)。经过修改,它可以显示可重新编程的电子飞行仪表,代替或与传统的圆形表盘仪表一起使用,包括主飞行显示器、多功能显示器、平视显示器(插图)和各种系统和/或导航显示器。它可以配置具有适当力负荷的传统飞行控制系统或电传操纵侧臂性能控制系统。当采用玻璃座舱配置时,它代表了一种高性能、技术先进的飞机。它可以与其自己的 180 度窗外视觉系统(如图所示)一起使用,也可以与广角视觉系统一起使用。使用该设备的研究包括对飞行显示器(地形描绘合成视觉 PFD/HUD、辅助地形显示器、NEXRAD 显示器、抬头和俯视飞行引导空中高速公路显示器、主姿态指示器和备用姿态指示器、附加或便携式导航显示器)的调查、飞行控制(常规和电传性能控制)、故障期间的飞行员表现(自动驾驶仪、俯仰配平、ADI 故障导致部分面板、从异常姿态中恢复)和飞行员决策(使用天气显示器和/或信息来避免恶劣天气)的调查。数据收集功能包括飞行性能、视频和音频数据的数字捕获。

使用机器学习检测深层的声音
随着深度学习技术的快速发展,合成媒体的创建,尤其是深层的假声音,已经变得越来越复杂且易于访问。这在维持基于音频的内容的信任和真实性方面构成了重大挑战。在响应中,该项目提出了一种基于机器学习的方法来检测深层的假声音。该项目首先策划了一个由真实和深厚的假语音样本组成的多样化数据集,涵盖了各种人口统计学,口音和情感表达。预处理技术用于清洁和标准化音频数据,然后进行功能提取以捕获语音信号的相关特征。用于模型开发,采用了复发层增强的卷积神经网络(CNN)体系结构,从而利用了其从音频的频谱图来学习空间和时间特征的能力。该模型使用分类横向渗透损失在准备好的数据集上进行了训练,并通过反向传播进行了优化。对训练的模型进行评估是在单独的测试集上进行的,测量诸如准确性,精度,回忆和F1评分之类的性能指标。后处理方法,包括阈值和平滑,用于完善模型的预测并增强鲁棒性。所提出的方法提供了一个有希望的框架,用于检测音频内容中深层的虚假声音,这有助于努力打击错误信息的传播并保留数字媒体的完整性。但是,跨学科的持续研究和协作对于应对新兴挑战并确保负责任的伪造检测技术至关重要。

使用边缘计算框架
摘要:在现实捕捉技术和人工智能(AI)的进步驱动的驱动到施工站点上,图像分类越来越多地用于自动化项目监视。部署实时应用程序仍然是一个挑战,尤其是在远程施工站点上,由于建筑物内的高信号衰减,电信支持或访问有限。为了解决此问题,本研究提出了一个有效的启用边缘计算的图像分类框架,以支持实时构造AI应用程序。使用Mobilenet转移学习开发了轻量级的二进制图像分类器,然后进行量化过程,以降低模型大小,同时保持准确性。组装了一个完整的Edge计算硬件模块,包括Raspberry Pi,Edge TPU和电池等组件,并将多模式软件模块(包含视觉,文本和音频数据)集成到边缘计算环境中以启用智能图像分类系统。部署了两项涉及材料分类和安全检测的实际案例研究,以证明拟议框架的有效性。结果证明了开发的原型成功同步多模式机制,并在分化材料中达到了零延迟,并识别危险的指甲而没有任何Internet连接。建筑经理可以利用开发的原型来促进集中的管理工作,而不会损害准确性或计算资源的额外投资。这项研究为未来的建筑工作站点启用边缘的“智能”铺平了道路,并促进实时的人类技术互动,而无需高速互联网。
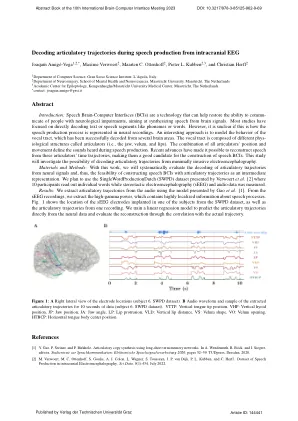
从颅内脑电图解码言语产生过程中的发音轨迹
简介:语音脑机接口 (BCI) 是一种可以帮助神经系统障碍患者恢复交流能力的技术,旨在从脑信号合成语音。大多数研究都集中于直接解码文本或语音片段,如音素或单词。然而,目前尚不清楚语音生成过程是否在神经记录中以这种形式呈现。一种有趣的方法是模拟声道的行为,该行为已从多个大脑区域成功解码。声道由称为发声器官的不同生理结构组成(即下颌、软腭和嘴唇)。所有发声器官的位置和运动的组合决定了语音生成过程中听到的声音。最近的进展使得从这些发声器官的时间轨迹重建语音成为可能,使它们成为构建语音 BCI 的良好候选者。本研究将探讨从微创脑电图解码发声轨迹的可能性。材料与方法:通过这项工作,我们将系统地评估从神经信号中解码发声轨迹,从而评估构建以发声轨迹为中间表示的语音 BCI 的可行性。我们计划使用 Verwoert 等人 [2] 提出的 SingleWordProductionDutch (SWPD) 数据集,其中 10 位参与者读出单个单词,同时测量立体定向脑电图 (sEEG) 和音频数据。结果:我们使用 Gao 等人 [1] 提出的模型从音频中提取发声轨迹。从 sEEG 记录中提取高伽马功率,其中包含有关语音过程的高度本地化信息。图 1 显示了 SWPD 数据集中植入其中一名受试者的 sEEG 电极的位置,以及来自一次记录的发声轨迹。我们训练一个线性回归模型,直接从神经数据预测发音轨迹,并通过与实际轨迹的相关性来评估重建。

使用神经技术支持的智能级联 U-Net 模型进行脑肿瘤分割
据神经病学专家介绍,脑肿瘤对人类健康构成严重威胁。脑肿瘤的临床识别和治疗在很大程度上依赖于准确的分割。脑肿瘤的大小、形状和位置各不相同,这使得准确的自动分割成为神经科学领域的一大障碍。U-Net 凭借其计算智能和简洁的设计,最近已成为解决医学图片分割问题的首选模型。局部接受场受限、空间信息丢失和上下文信息不足的问题仍然困扰着人工智能。卷积神经网络 (CNN) 和梅尔频谱图是这种咳嗽识别技术的基础。首先,我们在各种复杂的设置中组合语音并改进音频数据。之后,我们对数据进行预处理以确保其长度一致并从中创建梅尔频谱图。为了解决这些问题,提出了一种用于脑肿瘤分割 (BTS) 的新型模型,即智能级联 U-Net (ICU-Net)。它建立在动态卷积的基础上,使用非局部注意力机制。为了重建脑肿瘤的更详细空间信息,主要设计是两阶段级联 3DU-Net。本文的目标是确定最佳可学习参数,以最大化数据的可能性。在网络能够为 AI 收集长距离依赖关系之后,将期望最大化应用于级联网络的横向连接,使其能够更有效地利用上下文数据。最后,为了增强网络捕捉局部特征的能力,使用具有局部自适应能力的动态卷积代替级联网络的标准卷积。我们将我们的结果与其他典型方法的结果进行了比较,并利用公开的 BraTS 2019/2020 数据集进行了广泛的测试。根据实验数据,建议的方法在涉及 BTS 的任务上表现良好。肿瘤核心(TC)、完整肿瘤、增强肿瘤分割BraTS 2019/2020验证集的Dice评分分别为0.897/0.903、0.826/0.828、0.781/0.786,表明在BTS中具有较高的性能。