机构名称:
¥ 1.0
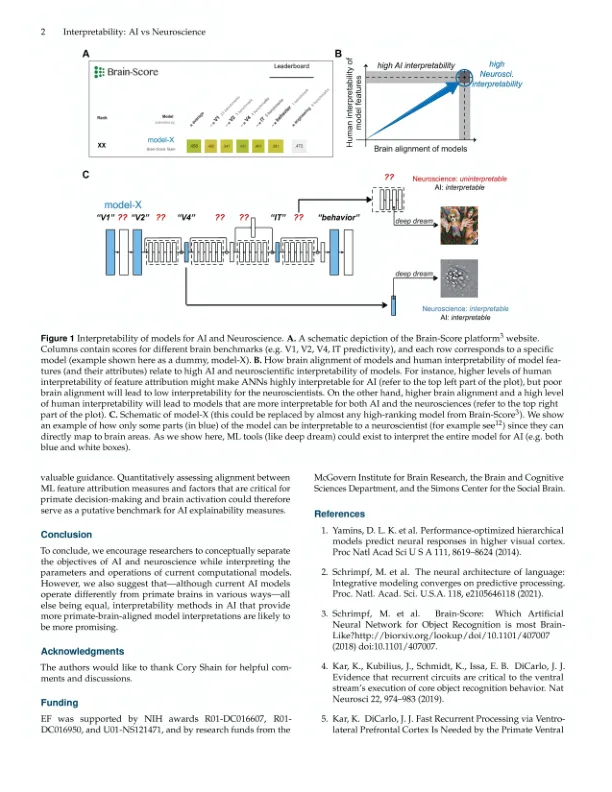
基于机器学习 (ML) 的模型得出的关于大脑功能的计算显式假设最近彻底改变了神经科学 1、2。尽管这些人工神经网络 (ANN) 具有前所未有的能力来捕捉生物神经网络 (大脑) 中的反应 (图 1A;参见 3 进行全面评论),并且我们可以完全访问所有内部模型组件 (与大脑不同),但 ANN 通常被称为可解释性有限的“黑匣子”。然而,可解释性是一个多方面的构造,在不同领域有不同的使用方式。特别是,人工智能 (AI) 中的可解释性或可解释性工作侧重于理解不同模型组件如何影响其输出 (即决策)。相比之下,ANN 的神经科学可解释性需要模型组件和神经科学构造 (例如,不同的大脑区域或现象,如复发 4 或自上而下的反馈 5 ) 之间的明确一致性。鉴于人们普遍呼吁提高人工智能系统的可解释性 6 ,我们在此强调了这些不同的可解释性概念,并认为 ANN 的神经科学可解释性可以与人工智能的持续努力并行但独立地进行。某些 ML 技术(例如,深度梦境,见图 1C)可以在这两个领域中得到利用,以探究哪种刺激可以最佳地激活特定模型特征(通过优化实现特征可视化),或者不同特征如何影响模型的输出(特征归因)。然而,如果没有适当的大脑对齐,某些特征(图 1C 中模型的非蓝色部分)对于神经科学家来说仍然是无法解释的。
人工智能与神经科学中人工神经网络模型的可解释性
主要关键词


相关文件推荐