机构名称:
¥ 8.0
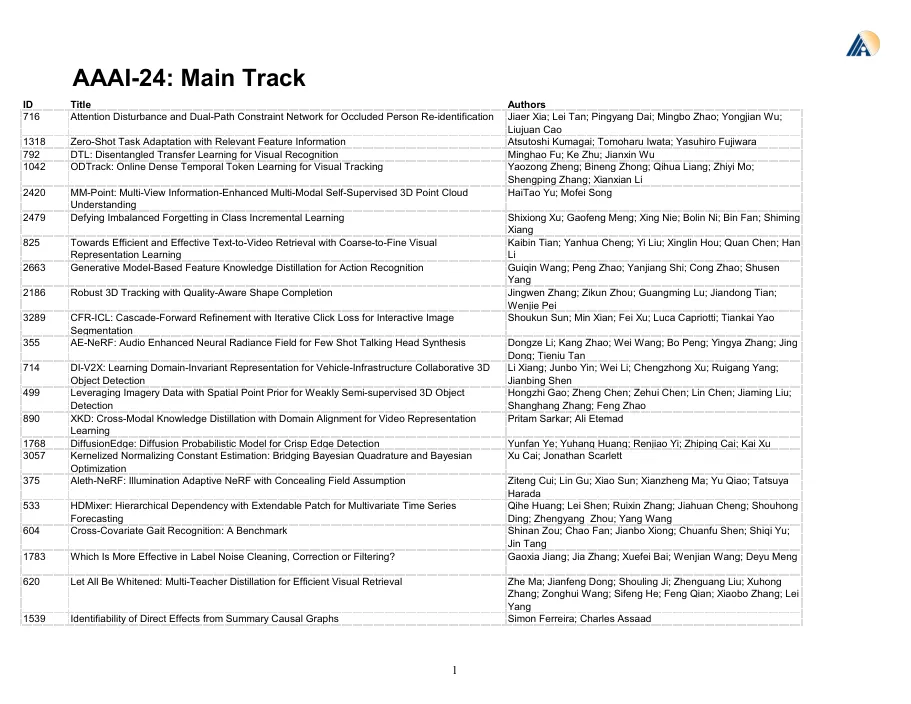
Haokun Chen; Yao Zhang; Denis Krompass; Jindong Gu; Volker Tresp 909 Auto-Prox: Training-Free Vision Transformer Architecture Search via Automatic Proxy Discovery Zimian Wei; Peijie Dong; Zheng Hui; Anggeng Li; Lujun Li; Menglong Lu; Hengyue Pan; Dongsheng Li 1661 Follow Your Pose: Pose-Guided Text-to-Video Generation Using Pose-Free Videos Yue Ma; Yingqing HE; Xiaodong Cun; Xintao Wang; Siran Chen; Xiu Li; Qifeng Chen 610 Style2Talker: High-Resolution Talking Head Generation with Emotion Style and Art Style Shuai Tan; Bin Ji; Ye Pan 1487 Colorizing Monochromatic Radiance Fields Yean Cheng; Renjie Wan; Shuchen Weng; Chengxuan Zhu; Yakun Chang; Boxin Shi 832 SAM-PARSER: Fine-Tuning SAM Efficiently by Parameter Space Reconstruction Zelin Peng; Zhengqin Xu; Zhilin Zeng; Xiaokang Yang; Wei Shen
AAAI-24:主要轨道
主要关键词




相关文件推荐