
机构名称:
¥ 3.0
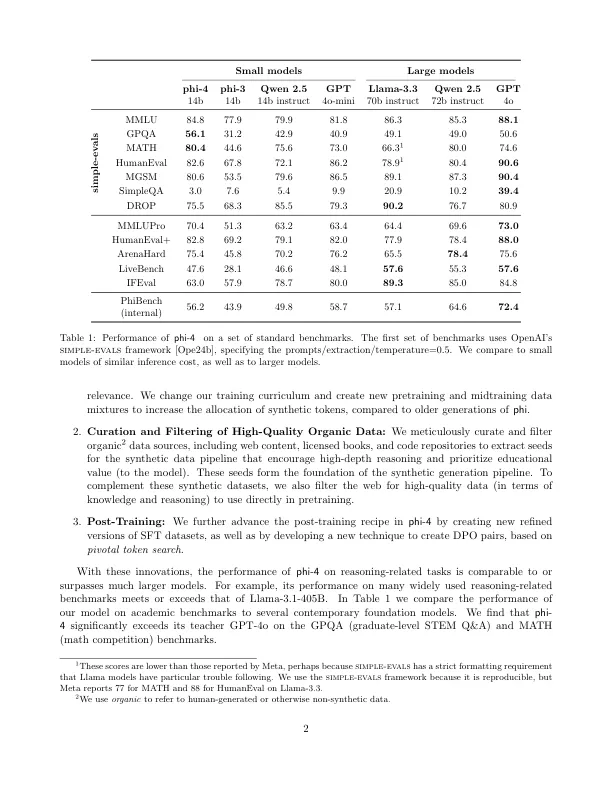
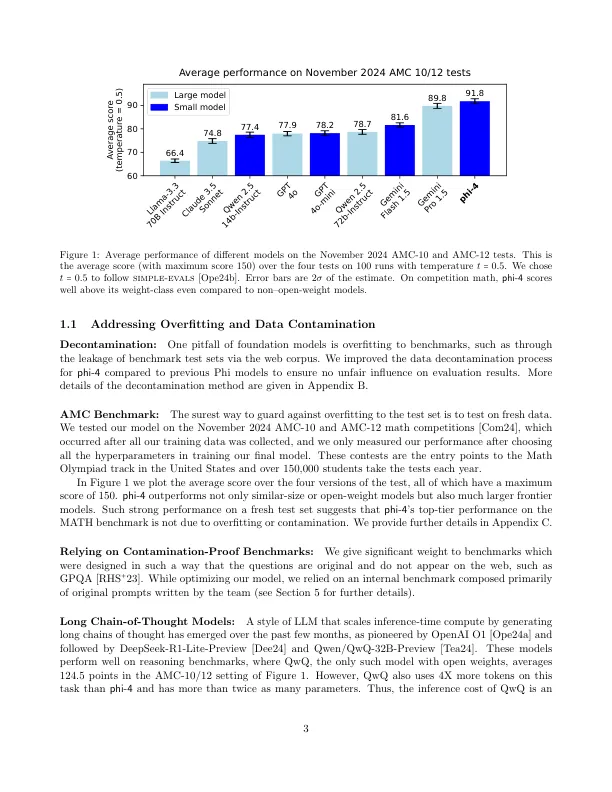
我们提出了 phi-4,这是一个拥有 140 亿个参数的语言模型,其开发方法主要关注数据质量。与大多数语言模型不同,这些模型的预训练主要基于 Web 内容或代码等有机数据源,而 phi-4 则在整个训练过程中策略性地整合了合成数据。虽然 Phi 系列中的先前模型在很大程度上提炼了教师模型(特别是 GPT-4)的功能,但 phi-4 在以 STEM 为中心的 QA 功能方面大大超越了教师模型,这证明我们的数据生成和后训练技术超越了提炼。尽管对 phi-3 架构的改动很小,但由于数据、训练课程的改进和后训练方案的创新,phi-4 相对于其规模实现了强劲的性能——尤其是在以推理为重点的基准上。
Phi-4 技术报告
主要关键词



相关文件推荐





























