机构名称:
¥ 4.0
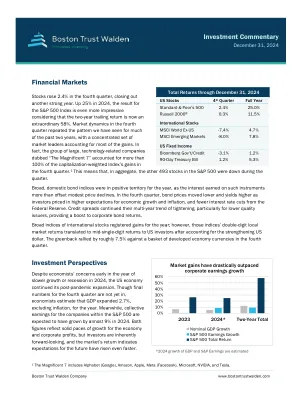
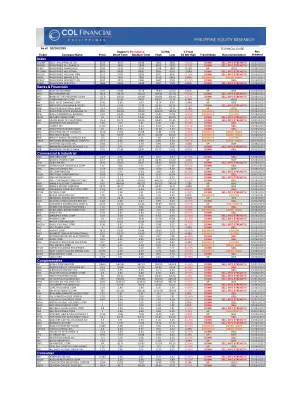
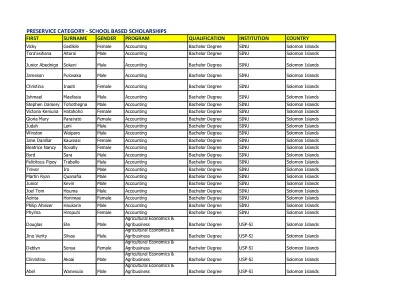
本文介绍了使用大语言模型(LLMS)自动生成学术金融论文的过程。它通过生成数百篇有关股票回报可预测性的完整论文来证明该过程的功效,这是一个特别适合我们的插图的主题。我们首先从会计数据中挖掘了超过30,000个潜在股票回报预测信号,并应用Novy-Marx和Velikov(2024)“分析异常”协议,以生成通过该协议严格标准的96个信号的标准化“模板报告”。每个报告详细介绍了一个信号的性能,可预测库存的回报,并将其基准为其他200多个已知异常。最后,我们使用最先进的LLM为每个信号生成三个不同的学术论文完整版本。不同的版本包括信号的创意名称,包含自定义介绍,为观察到的可预测性模式提供不同的理论理由,并为支持其各自主张的现有(有时是想象中的)文献纳入了引用。该实验说明了AI提高财务研究效率的潜力,但也是一个警示性的故事,说明了如何滥用它来工业化Harking(已知结果后假设)。
AI驱动(金融)奖学金Robert Novy-Marx和...
主要关键词





相关文件推荐