XiaoMi-AI文件搜索系统
World File Search System归因

Montrage:监视生成扩散模型归因培训
摘要。扩散模型彻底改变了图像产生,正面临与知识产权有关的挑战。当生成的图像受培训数据中受版权保护的图像的影响时,就会出现这些挑战,这是互联网收集的数据中合理的情况。因此,从训练数据集中指向有影响力的图像(称为数据归因的任务)对于内容起源的透明度至关重要。我们介绍了蒙特雷奇(Montrage),这是一种开创性的数据归因方法。与分析模型后训练后的现有方法不同,蒙特拉奇(Montrage)整合了一种新型技术,可以通过内部模型表示在整个培训中监测世代。它是针对定制的分化模型量身定制的,其中训练动力学访问是一个实际的假设。这种方法,再加上新的损失功能,在保持效率的同时提高了性能。在两个粒度级别上评估了蒙特莱奇的优势:概念间和概念内,以高精度为单位的最新方法。这取代了Montrage对扩散模型的见解及其对AI Digital-Art版权解决方案的贡献。

北极熔体异常的特征归因
我们工作的重点是改善气候模型中异常的解释性,并促进我们对北极熔体动态的理解。北极和南极冰盖正在迅速融化并增加了淡水径流,这显着导致了全球海平面上升。了解在这些地区驱动融雪的机制至关重要。ERA5是极地气候研究中广泛使用的重新分析数据集,可提供广泛的气候变量和全球数据同化。但是,其融雪模型采用了一种能量不平衡的方法,可能会过度简化表面熔体的复杂性。相反,冰川能量和质量平衡(GEMB)模型结合了其他物理过程,例如积雪,FIRN致密化和融化液化/重新冻结,提供了表面熔体动力学的更详细的表示。在这项研究中,我们专注于分析格陵兰冰盖的表面融雪材料,并使用ERA5和GEMB模型中异常熔体事件的特征归因。我们提出了一种新型的无监督归因方法,利用反对解释方法来分析ERA5和GEMB中检测到的异常。我们的异常检测结果通过模仿地面真实数据进行验证,并针对既定的特征排名方法进行了评估,包括XGBoost,Shapley值和随机森林。我们的归因框架标识了每种模型背后的物理和气候特征驱动熔体异常的特征。这些发现证明了我们的归因方法在增强气候模型中异常的解释性并促进我们对北极熔体动力学的理解方面的实用性。
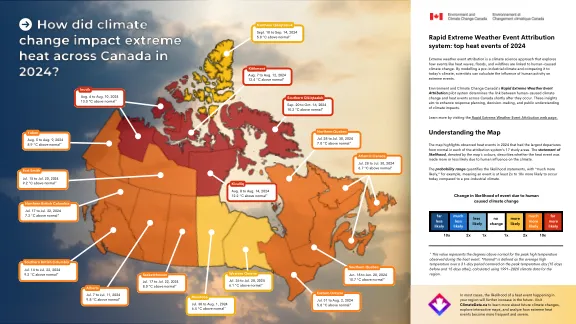
快速极端天气事件归因系统
极端天气事件归因是一种气候科学方法,它探讨了热浪,洪水和野火等事件如何与人为引起的气候变化相关。通过对工业前的气候进行建模并将其与当今气候进行比较,科学家可以计算人类活动对极端事件的影响。

人工智能归因知识在艺术品评估中的作用
摘要 越来越多的艺术品由机器通过算法创作,几乎不需要人类的输入。然而,人们对机器生成的艺术品的态度和评价知之甚少。当前的研究调查了(a)个人是否能够准确区分人造艺术品和人工智能生成的艺术品,以及(b)归因知识(即有关谁创作了内容的信息)在他们评价和接受艺术品中的作用。数据是使用 Amazon Turk 样本从在 Qualtrics 上设计的两个调查实验中收集的。研究结果表明,个人无法准确识别人工智能生成的艺术品,他们很可能将具象艺术与人类联系起来,将抽象艺术与机器联系起来。归因知识和艺术品类型(具象与抽象)之间也存在对购买意向和艺术品评价的相互作用。

开发卫星异常分析和归因的综合应用程序
为了满足我们技术社会的需求,近地空间的卫星数量正在迅速增加。这些卫星预计将在受到强烈粒子辐射的轰击时持续运行,这些辐射可能会损坏电子元件,导致暂时故障、性能下降或整个系统/任务失败。我们尽一切努力设计能够承受恶劣环境的卫星,但在轨道上仍然会出现问题。当出现问题时,有必要找出原因,以便采取适当的措施保护资产并恢复正常运行。然而,诊断与空间天气相关的异常具有挑战性,因为它需要广泛的环境信息、工程知识和专业知识。我们的目标是通过提供将所有必要组件整合在一起并简化最终用户的分析过程的工具来实现有效的异常分析和归因。在这里,我们讨论了我们为构建全面的卫星异常归因工具所做的努力。我们介绍了一些正在进行的项目,包括开发高能电子辐射带模型 (SHELLS)、卫星充电评估工具 (SatCAT) 和太阳质子访问模型 (SPAM)。 SHELLS 电子辐射带模型使用神经网络来绘制从低空到高空填充内磁层的实时高能电子通量。一旦建立了映射,就可以仅使用近乎实时的 POES/MetOp 数据来指定过去和未来的高能电子通量。SatCAT 工具是一个在线系统,允许用户创建在轨卫星当前和历史内部充电水平的时间线,以便与异常时间进行比较。该工具是可配置的,允许用户生成和查看其卫星的内部充电水平以及设计参数,例如屏蔽厚度和材料。最后,太阳质子接入模型 (SPAM) 使用低空 POES/MetOp 测量来绘制整个磁层的太阳质子通量。

关于极端气候事件归因的四个博士职位
,候选人将分析多年的时间复合方面,与季节性和年度尺度上表面温度异常的关系以及与大气的低频变异性的关系。此外,将使用应用于不同复杂性的数值气候模型的罕见事件算法产生大型多年干旱的大型数据集。最后,将开发非平稳的极值模型,以量化长期极端干旱发生概率的未来变化,并为最近事件带来可靠的归因陈述。

2型糖尿病在患者症状归因中的作用...
摘要 - 电子显微镜图像中轴突和髓磷脂的分割使神经科医生可以突出轴突的密度和周围髓磷脂的厚度。这些特性对于预防和预测白质疾病具有极大的兴趣。通常手动执行此任务,这是一个漫长而乏味的过程。我们提出了用于通过机器学习计算该细分的方法的更新。我们的模型基于U-NET网络的体系结构。我们的主要贡献包括在u-Net网络的编码器部分中使用转移学习,以及分割时测试时间增加。我们使用在Imagenet 2012数据集中预先训练的Se-Resnet50骨干重量。我们使用了23张图像的数据集,其中包括相应的分段掩模,这也是由于其极小的尺寸而具有挑战性的。结果表明,与最先进的表演相比,测试图像的平均精度为92%。也必须注意,可用样品是从call体的老年人中取的。与从脊髓或健康个体的视神经中采集的样品相比,这是一种额外的困难,具有更好的轮廓和碎屑较少。索引术语 - 深度学习,分割,髓磷脂,轴突,G比,卷积神经网络(CNN),电子显微镜

签证:带视觉源归因的检索增强生成
源文档的。 此类源归因042方法使用户可以检查输出的043可靠性(Asai等人。 ,2024)。 044 However, text-based generation with source attri- 045 bution faces several issues: First, citing the source 046 at the document level could impose a heavy cogni- 047 tive burden on users ( Foster , 1979 ; Sweller , 2011 ), 048 where users often struggle to locate the core ev- 049 idence at the section or passage level within the 050 dense and multi-page document. 尽管有051个粒度不匹配可以通过基于052通道引用的生成方法来解决 - 链接 - 053对特定文本块的答案,它需要非054个琐碎的额外工程工作,以匹配文档源中的块055。 此外,源文档中的视觉高-056照明文本块对用户的直观更加直观,但是它仍然具有挑战性,因为它需要控制文档渲染,这是059,它并不总是可以访问,例如PDF方案中。 060受到最新文档屏幕截图EM- 061床上用品检索范式的启发 - 放下文档 - 062 Ment Processing模块,直接使用VLM 063来保留内容完整性和编码Doc-064 UMent ument屏幕截图(Ma等人。 ,2024),065,我们询问源归因是否也可以在066中添加到如此统一的视觉范式中,以es- 067 tablish tablish tablish tablish a Tablish a Tablish a既是视觉,端到端可验证的RAG 068管道,既是用户友好且有效? 069为此,我们提出了通过VI Sual s usce a ttribution(Visa)的检索增加的070代。。此类源归因042方法使用户可以检查输出的043可靠性(Asai等人。,2024)。044 However, text-based generation with source attri- 045 bution faces several issues: First, citing the source 046 at the document level could impose a heavy cogni- 047 tive burden on users ( Foster , 1979 ; Sweller , 2011 ), 048 where users often struggle to locate the core ev- 049 idence at the section or passage level within the 050 dense and multi-page document.尽管有051个粒度不匹配可以通过基于052通道引用的生成方法来解决 - 链接 - 053对特定文本块的答案,它需要非054个琐碎的额外工程工作,以匹配文档源中的块055。此外,源文档中的视觉高-056照明文本块对用户的直观更加直观,但是它仍然具有挑战性,因为它需要控制文档渲染,这是059,它并不总是可以访问,例如PDF方案中。060受到最新文档屏幕截图EM- 061床上用品检索范式的启发 - 放下文档 - 062 Ment Processing模块,直接使用VLM 063来保留内容完整性和编码Doc-064 UMent ument屏幕截图(Ma等人。,2024),065,我们询问源归因是否也可以在066中添加到如此统一的视觉范式中,以es- 067 tablish tablish tablish tablish a Tablish a Tablish a既是视觉,端到端可验证的RAG 068管道,既是用户友好且有效?069为此,我们提出了通过VI Sual s usce a ttribution(Visa)的检索增加的070代。071在我们的方法中,大型视觉模型072(VLM)处理单个或多个检索的文档图像,不仅为074产生了对074用户查询的答案,而且还返回了075框架内的相关区域内的相关区域。076如图1所示,此方法通过视觉上指示文档中的确切078位置来启用di-077 rect归因,从而允许用户在080原始上下文中快速检查生成答案的原始上下文中的支持证据。VLMS 081不受文档格式或渲染的限制,082

dag:对归因图的深度自适应和无生成的社区检测
对归因图的社区检测,具有丰富的语义和拓扑信息为现实世界网络分析,尤其是在线游戏中的用户匹配提供了巨大的潜力。图形神经网络(GNNS)最近启用了深度图(DGC)方法,从语义和拓扑信息中学习群集分配。但是,它们的成功取决于与社区数量有关的先验知识,由于收购的高成本和隐私问题,这是不现实的。在本文中,我们研究了与事先的社区检测问题,称为𝐾 -free社区检测问题。为了解决这个问题,我们提出了一种新颖的深层自适应模型(DAG),以供社区检测,而无需指定先前的𝐾。DAG由三个关键组件组成,即带有屏蔽属性重新构造的节点表示模块,一个社区关联读数模块以及具有组稀疏性的社区编号搜索模块。这些组件使DAG能够将非差异性网格搜索的过程转换为社区编号,即存在的DGC方法中的离散超级参数,将其转换为可区分的学习过程。以这种方式,DAG可以同时执行社区检测和端到端的社区编号搜索。为了减轻现实世界应用中社区标签的成本,我们设计了一种新的指标,即使标签不可行,也可以评估社区检测方法。在五个公共数据集和一个现实世界的在线手机游戏数据集上进行了广泛的离线实验

我,机器人:人类的外表和思维归因与机器人的危险感知有何关系
摘要 社交机器人在外观和行为上越来越像人类。然而,大量研究表明,这些机器人往往会引起恐惧、危险和威胁等负面情绪。在本研究中,我们探讨了类人外表和心智归因是否以及如何导致这些负面情绪,并阐明了可能的潜在机制。向参与者展示了机械、人形和安卓机器人的图片,并评估了这三种机器人的身体拟人化(研究 1-3)、心智对能动性和经验的感知归因(研究 2 和 3)、对人机独特性的威胁以及对人类及其身份的损害。复制早期研究,人机独特性介导了拟人化外观对人类及其身份感知损害的影响,这种介导是由于机器人的拟人化外观。感知能动性和经验对人机独特性没有表现出类似的中介作用,但与对人类及其身份的感知损害呈正相关。我们讨论了可能的解释。