XiaoMi-AI文件搜索系统
World File Search System机器人学

机器人学中的未成年人
AE/BMED/ME/ECE/CS 4699机器人或自主系统(3小时)的本科研究可用于满足4个核心要求之一。这项研究必须与机器人学院成员一起完成,并需要一份最终报告,该报告强调其与各自的核心的联系:自治,控制,机械和感知。

机器人学的简洁百科全书
使用条款这是一项受版权保护的工作,McGraw-Hill Companies,Inc。(“ McGraw-Hill”)及其许可人保留工作和工作中的所有权利。使用这项工作应遵守这些条款。除非1976年的《版权法》允许,并且有权存储和检索一份作品的副本,您可能不会反编译,拆卸,反向工程,复制,复制,ify,创建基于,传输,分发,分发,发放,出售,出售,出版或出版的工作或任何一部分,而没有McGraw-Hill的任何一部分。您可以将工作用于自己的非商业和个人用途;严格禁止对工作的任何其他用途。如果您不遵守这些条款,则可以终止使用工作的权利。提供的工作是“原样”。McGraw-Hill及其许可人对使用工作的准确性,充分性或完整性或结果不保证或保证,包括可以通过超链接或其他方式通过工作访问的任何信息,并明确不违反任何保证,明确或暗示,包括但不限于商品或适用于商品的植入保证的属性或适用于众所周知。McGraw-Hill及其许可方不保证或保证工作中包含的功能将符合您的要求,否则其操作将无验证或无错误。McGraw-Hill及其许可人不应对您或其他任何人承担任何不准确,错误或遗漏的责任,无论原因,在工作中或对此造成的任何损害。McGraw-Hill对通过工作访问的任何信息的内容不承担任何责任。在任何情况下,麦格劳 - 希尔(McGraw-Hill)和/或其许可人不得对由于使用或无法使用工作而造成的任何间接,偶然,特殊,惩罚性,结果,结果或类似损害均承担责任,即使已告知其中任何一个损害的可能性。这种责任限制应适用于任何索赔或造成任何索赔或引起合同,侵权或其他索赔。


模仿机器人学:调查 - 虹膜
交互式模仿学习(IIL)是模仿学习(IL)的一个分支,在机器人执行过程中,间歇性地提供了人类反馈,从而可以在线改善机器人的行为。近年来,IIL越来越开始开拓自己的空间,作为解决复杂机器人任务的有前途的数据驱动替代方案。IIL的优势是双重的,1)它是有效的,因为人类的反馈将机器人直接引导到了改善行为(与增强学习(RL)相反(RL),必须通过试用和错误发现行为(必须通过试用和错误发现),而2),并且2)是强大的,因为它是强大的,因为分配者和教师的分配量直接在教师身上是匹配的,并且在教师中匹配的范围是在范围内逐渐匹配的,并且在教师中匹配的范围是在范围内的指导,而逐渐匹配的是,教师的自我反射是及格的, o line Ile IL方法,例如行为克隆)。尽管有机会,但文献中的术语,结构和适用性尚不清楚,也尚未确定,从而减慢了其发展,因此,研究了创新的表述和发现。在本文中,我们试图通过对统一和结构的领域进行调查来促进新从业人员的IIL研究和较低的入境障碍。此外,我们旨在提高人们对其潜力,已完成的工作以及仍在开放的研究问题的认识。

从口语学习机器人学习
自动化决策系统越来越多地用于我们的日常生活中,例如在贷款,保险和医疗服务的背景下。一个挑战是,这些决策系统可以证明对弱势群体的歧视(Dwork等,2012)。为了减轻此问题,已经提出了公平的限制(Hardt等,2016; Dwork等,2012),例如寻求实现某些统计奇偶校验属性。尽管公平的机器学习已经进行了广泛的研究,但大多数工作都考虑了静态设置,而无需考虑决策的顺序反馈效果。同时,算法决定可能会通过与社会的反馈循环来改变数据中基本统计模式的变化。反过来,这会影响决策过程;

认知机器人学中的常识知识
机器人技术中最大的挑战之一是在未知对象上执行未知环境中执行未知任务所需的概括。对我们人类而言,通过我们可以访问的常识性知识来简化这一挑战。对于认知机器人技术,代表和获取常识性知识是一个相关问题,因此我们进行系统的文献综述,以调查认知机器人技术中常识性知识开发的当前状态。在此评论中,我们将六个搜索引擎上的关键字搜索与六个相关评论的滚雪球搜索结合在一起,从而产生了2,048个不同的出版物。应用预定义的包含和排除标准后,我们分析了其余52个出版物。我们的重点在于使用常识性知识的用例和域,所考虑的常识方面,用作常识知识来源的数据集/资源以及评估这些方法的方法。此外,我们发现了从知识表示与推理与认知机器人界的研究之间的术语差异。通过查看Zech等人进行的广泛审查来研究这种鸿沟。(《国际机器人研究杂志》,2019,38,518–562),尽管有类似的目标,但我们还是没有重叠的出版物。

CSE 598:机器人学中的感知
课程目标和预期的学习成果,该研究生课程向学生介绍了计算机视野,其广泛的目标是创建用于处理视觉信号(图像,视频等)的算法和系统用于低级,中级和高级感知任务。本课程介绍了从了解针孔相机的成像过程开始的广泛的原理和技术,了解镜头,镜头,梯度和边缘,3D结构估计,运动估计,运动估算,对感知任务,例如形状识别,表面识别,面部识别,活动识别,活动识别,现场识别和场景。班级将是课堂讲座和讨论以及个人和小组项目的混合。
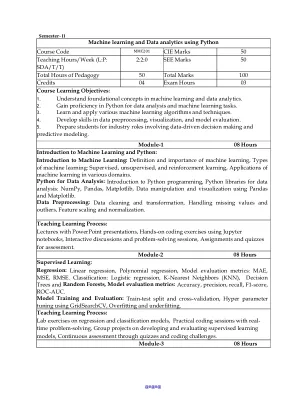
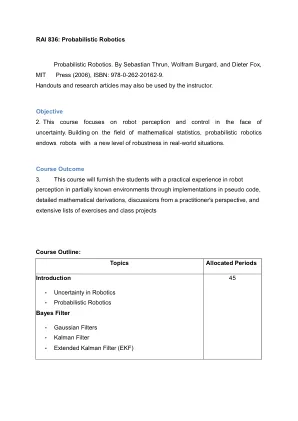
机器人学学期的管理经济学V
2对于一个给定的培训数据示例存储在.csv文件中,并实现并演示候选算法算法输出与培训示例一致的所有假设集的描述。3编写一个程序,以演示基于决策树的ID3算法的工作。使用适当的数据集来构建决策树并应用此知识来对新样本进行分类。4编写一个程序,以实现幼稚的贝叶斯分类器,以将存储为.csv文件存储的示例培训数据集。考虑了很少的测试数据集,计算分类器的准确性。5编写一个程序来实现k-nearest邻居算法以对虹膜数据集进行分类。打印正确与错误的预测。6通过实现反向传播算法并使用适当的数据集测试相同的人工神经网络。7编写一个程序,以在给定数据集上使用残差图演示回归分析。
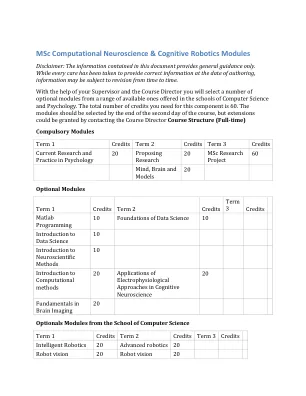
MSC计算神经科学与认知机器人学模块
该模块的目的和学习目标:该模块将介绍在数据分析中使用编程。所涵盖的主题将包括:编程到底是什么,以及为什么如此有用;与编程语言和命令行环境进行交互;基本编程概念(命令,数据结构,包括向量和矩阵,计算,编程);编程技术(流量控制,模块,功能和.m文件,文件输入/输出,图形),最后,学生将完成一个结构化的编程练习,旨在制定程序以执行简单分析。这将构成课程评估的基础。