XiaoMi-AI文件搜索系统
World File Search System高通量

通过高通量测序检测外来 DNA...
尽管几种新型育种技术 (NBT) 的出现正在彻底改变农业生产过程,但尚未提供对其监管所需的技术信息。本文表明,高通量 DNA 测序可有效检测基因组编辑水稻中意外残留的外来 DNA 片段。本文提出了一种简单的 k 聚体检测方法,并通过一系列计算机模拟和实际数据分析进行了验证。数据显示,可以检测到 20 个核苷酸的短外来 DNA 片段,如果平均测序深度为 30 或更多,则忽略该片段的概率为 10 − 3 或更低,而错误命中数平均少于 1。该方法已应用于实际测序数据,并成功证明了外部 DNA 片段的存在和不存在。此外,我们的深入分析还发现了当前 DNA 测序技术的一些弱点。因此,为了进行严格的安全性评估,建议结合使用 k 聚体检测和另一种方法(例如南方印迹分析)。本研究的结果将为 NBT 产品的调控奠定基础,在 NBT 产品的生成过程中,外来 DNA 会被利用。

1st ICIQ高通量实验研讨会
Fernando Bravo知识与技术转移负责Bravo博士在Rovira I Virgili大学(1997-2000)完成了博士学位。在埃默里大学(Emory University)(2001-2003)的博士后阶段之后,布拉沃(Bravo)博士被聘为GlaxoSmithkline Verona化学发展部(意大利; 2003-2010)的化学发展部的合成化学家,在那里他参加了各个阶段的开发阶段(从开发项目(从临时性注册到注册和发射)和开发化学团队的辅助化学家。Bravo博士于2010年加入ICIQ,目的是创建和领导CSOL部门直到2023年,重点关注ICIQ自己的技术的价值,并与行业管理合同研究项目。在这个职位上,他监督了大约40个价值项目的开发团队的一部分。Bravo博士一直是各个区域,国家和国际项目的首席研究员,并与工业合作伙伴(尤其是与制药部门有关的工业伙伴)协调合同研究项目。尤其是Bravo博士在设计,优化和扩展制药公司的优化和按需合成项目中的合成路线上应用了他的专业知识。他以> 30份出版物和8份专利申请进行计数。Bravo博士拥有AEI的R3认证。目前,他是ICIQ知识和技术转移部门的负责人。

CytoRADx:高通量、标准化生物剂量测定...
在大规模灾难中,例如大城市发生核爆炸,准确诊断大量人员的伤情,将稀缺的医疗资源用于最需要的人,至关重要。目前尚无经 FDA 批准的检测方法可用于诊断辐射暴露,而辐射暴露可能会导致复杂的、危及生命的伤害。为了弥补这一缺陷,我们通过改进和改进胞质分裂阻滞微核 (CBMN) 检测方法,将其作为一种高通量定量诊断检测,在辐射生物剂量测定方面取得了重大进展。经典的 CBMN 方法可量化由 DNA 损伤引起的微核 (MN),这种方法需要大量时间和专业人员,而且缺乏跨实验室的通用方法。我们开发了 CytoRADx e 系统来解决这些缺点,它采用标准化试剂盒、优化的检测方案、全自动显微镜和图像分析以及集成剂量预测。这些增强功能使 CytoRADx 系统能够获得高通量、标准化的结果,而无需专业劳动力或实验室特定的校准曲线。CytoRADx 系统已针对人类和非人类灵长类动物 (NHP) 进行了优化,以量化淋巴细胞中辐射剂量依赖性微核的形成,使用全血样本进行观察。细胞核和产生的微核使用我们提供的材料进行荧光染色并保存在耐用的显微镜载玻片上

网站:https://www.arl.army.mil/HTMDEC 高通量...
基于规则的人工智能 (AI) 和机器学习 (ML) 工具为探索信息格局提供了强大的途径,以发现用于极端条件(例如高应变率、高 g 负载、高温)的新材料。这些方法为探索用于防护和杀伤力应用的材料的新领域提供了巨大的机会,尤其是当与允许更大、更丰富的数据集、计算工具和数据基础设施进行协作的新方法相结合时。广义上讲,AI/ML 可用于增强合成-加工-表征流程中的各个步骤,用于规模桥接以从更易处理的实验方法中提取更多信息,并用于指导更广泛的研究循环。

mRNA 体外选择的高通量测序...
诺贝尔化学奖。体外选择对物理生物化学特别有吸引力,因为它能够仔细控制选择环境,从而能够探测各种现象,包括分子相互作用、折叠行为和进化途径。在体外选择过程中,具有所需特性的功能分子从大量随机(或半随机)序列中分离出来。这是通过选择、扩增和诱变的迭代循环实现的,直到最终的池中富含表现出所需特性的变体(图 1)。虽然体外选择通常应用于核酸,但当与肽展示技术相结合时,可以识别感兴趣的功能肽。特别是,mRNA 展示被广泛用于此目的,这将是本期观点的重点。

rosettearray平台用于定量高通量...
RosetteArray ® Platform for Quantitative High-Throughput Screening of Human Neurodevelopmental Risk Brady F. Lundin 1,2,3,* , Gavin T. Knight 3,4,* , Nikolai J. Fedorchak 4 , Kevin Krucki 4 , Nisha Iyer 1,3 , Jack E. Maher 3 , Nicholas R. Izban 3 , Abilene Roberts 3 , Madeline R. Cicero 3,Joshua F. Robinson 5,Bermans J. Iskandar 6,Rebecca Willett 4,7和Randolph S. Ashton和Randolph S. Ashton 1,3,4,8 1生物医学工程系,威斯康星州麦迪逊,麦迪逊大学,威斯康星州麦迪逊大学,美国威斯康星州53705,美国23705,美国2 Wisconsin Institute for Discovery, University of Wisconsin-Madison, Madison, WI 53715, USA 4 Neurosetta LLC, 330 N. Orchard Street Rm 4140A, Madison, WI 53715 USA 5 Center of Reproductive Sciences, Department of Obstetrics, Gynecology and Reproductive Sciences, University of California, San Francisco, San Francisco, CA 94143, USA 6 Department of Neurological Surgery, University of Wisconsin-Madison, School of Medicine and Public Health, Madison, WI 53705, USA 7 Departments of Statistics and Computer Science, University of Chicago, Chicago, IL 60637, USA 8 Lead Contact, correspondence: rashton2@wisc.edu *Equal contribution SUMMARY Neural organoids have revolutionized how human neurodevelopmental disorders (NDDs) are研究。然而,它们用于筛选复杂的NDD病因和药物发现的效用受到缺乏可扩展和可量化的推导格式的限制。在这里,我们描述了Rosettearray®

1st ICIQ高通量实验研讨会
Fernando Bravo知识与技术转移负责Bravo博士在Rovira I Virgili大学(1997-2000)完成了博士学位。在埃默里大学(Emory University)(2001-2003)的博士后阶段之后,布拉沃(Bravo)博士被聘为GlaxoSmithkline Verona化学发展部(意大利; 2003-2010)的化学发展部的合成化学家,在那里他参加了各个阶段的开发阶段(从开发项目(从临时性注册到注册和发射)和开发化学团队的辅助化学家。Bravo博士于2010年加入ICIQ,目的是创建和领导CSOL部门直到2023年,重点关注ICIQ自己的技术的价值,并与行业管理合同研究项目。在这个职位上,他监督了大约40个价值项目的开发团队的一部分。Bravo博士一直是各个区域,国家和国际项目的首席研究员,并与工业合作伙伴(尤其是与制药部门有关的工业伙伴)协调合同研究项目。尤其是Bravo博士在设计,优化和扩展制药公司的优化和按需合成项目中的合成路线上应用了他的专业知识。他以> 30份出版物和8份专利申请进行计数。Bravo博士拥有AEI的R3认证。目前,他是ICIQ知识和技术转移部门的负责人。
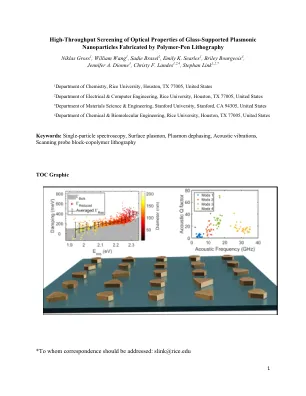
玻璃的光学特性的高通量筛选 -
!“#$%&'()*&&!+',“ $$”% - ',%。/!+'0%1“ 2'3)%&2 $” +'4-“ $ 5'67'02%)$ 2&!+'3)“ $ 25'3*8)/2*”&# +92 ..“:2); 7 <“*.. 2# +'=>)”'a“。#!$” $&

基于3D环的多功能高通量测定法 -
摘要我们开发了一个96孔板测定法,该测定法可以快速,可再现和12个高通量生成的3D心脏环,周围是可变形的光学透明13水凝胶(PEG)的已知刚度的柱子。人类诱导的多能干细胞衍生的14个心肌细胞,与正常的成年成人皮肤纤维细胞混合,以优化的3:1比例,15个自组织形成环形心脏构建体。免疫染色表明,16个纤维组成的基础层与玻璃接触,稳定上面的肌肉纤维。17个组织开始在D1处的支柱周围收缩,其分数缩短到18 d7,达到高原为25±1%,最多可保持14天。平均应力为19,根据收缩期间中央支柱的压实计算出1.4±0.4 mn/mm2。20心脏构建体概括了对钙和各种药物21(异丙肾上腺素,维拉帕米)的预期肌瘤反应,以及多菲替艾尔的心律失常作用。这种多功能22个高通量测定法允许多个原位机械和结构读出。23

高通量代谢组学预测药物
化学探针是了解生物系统的重要工具。然而,由于靶标和潜在化合物的组合空间巨大,传统的化学筛选无法系统地应用于寻找所有可能的药物靶标的探针。在这里,我们展示了一个克服这一挑战的新概念,即利用高通量代谢组学和过表达来预测药物-靶标相互作用。收集了用来自化学库的 1,280 种化合物处理的酵母的代谢组谱,并将其与可诱导的酵母膜蛋白过表达菌株的代谢组谱进行比较。通过匹配代谢组谱,我们预测了哪些小分子靶向哪些信号系统并恢复了已知的相互作用。在所研究的 86 个基因中生成了药物-靶标预测,包括难以研究的膜蛋白。测试和验证了这些预测的一个子集,包括布洛芬对 GPR 1 信号的新靶向。这些结果证明了使用高通量代谢组学预测真核蛋白的药物-靶标关系的可行性。