XiaoMi-AI文件搜索系统
World File Search SystemBinocular



用于神经形态空间情境观测的双目望远镜...
虽然基于事件的空间态势感知提供了显著的优势,但基于事件的传感范式也带来了传统基于帧的 SSA 所没有的新挑战。快速而微弱的点源很难在其他来源产生的虚假变化检测中识别出来,尤其是来自昆虫、蝙蝠和飞机的检测。神经形态传感器缺乏绝对亮度信息,当 RSO 和大气物体的轨迹从观察者的角度来看相似时,更难区分它们。虚假检测不仅限于大气伪影,也可能是由于传感器噪声造成的。虽然最近的神经形态传感器与旧型号相比已显著改善了噪声特性,但仍然希望尽可能接近本底噪声来检测越来越微弱的物体。

增强了双眼视觉的救援机器人
摘要:在自然灾害,事故,医疗紧急情况和其他事件等紧急情况下的救援工作充满了挑战和危险。考虑到救援人员的安全和救援任务的紧迫性,有必要使用救援机器人执行环境检测和救援任务。该项目旨在通过整合双眼视觉技术来增强搜索和救援机器人的功能。通过为这些机器人提供复杂的双目系统,我们旨在改善其深度感知,对象识别和整体情境意识。该项目将涉及与现有机器人平台集成的专业视觉系统的开发。最终目标是使救援机器人能够进行更有效的导航和反应能力,从而提高其在批判性搜索和救援任务中的效率和成功。
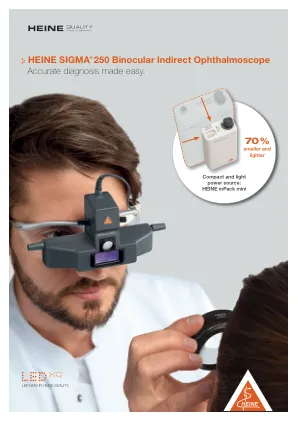
HeineSigma®250双眼间接眼镜
Heine Mpack Mini - Sigma 250的紧凑和光电源。新型高性能电源Heine Mpack Mini提供了从将用户绑在桌子,墙壁或静态电源来源的电缆上。重量仅为95 g,尺寸为44 x 23 x 101毫米,该移动电源现在约为大约。比其前身小70%。

神经形态双目系统完全基于事件的运动估计
摘要:随着人工视网膜的进步,神经形态计算在过去 20 年中已成为一个日益增长的研究领域。机器人、自动驾驶、医疗设备中的应用开始出现。然而,仍然存在一些主要问题,因为使用的方法过于频繁地模仿,甚至简单地适应为根本不同类型的数据而开发的标准基于帧的技术。这些技术通常处理批量数据,执行全局优化,同时忘记事件的基本性质。由于它们呈现场景的微小变化,我们认为在计算时应将其视为此类变化。本论文重点关注视觉里程计的案例,以开发完全基于事件的计算技术,利用现有的神经形态传感器的全部优势。使用无穷小更新,我们开发了低延迟算法,同时处理截然不同的场景动态。通过仔细分析事件流,我们相信可以在低计算成本下实现低延迟,这再次表明神经形态工程是减少计算机视觉能量足迹的一种方法。第一部分解决了屏幕跟踪问题。通过使用惯性模型,我们开发了一种高频跟踪解决方案,无需事先了解相关形状。第二组算法展示了如何从双目系统计算光流和深度,并以异步方式使用它们来计算视觉传感器自我运动估计。第三部分将前两个部分组合成一个虚拟模型,几乎不需要对场景进行任何假设即可恢复在线姿势。最后,最后一部分更深入地分析了基于事件的范式中时间的重要性,并描述了为实现正确和高效的时间处理而实施的开发框架解决方案。

管电压对旋转X射线阳极侵蚀的影响
本论文旨在为有视觉障碍的个体开发一个负担得起的立体视频导航系统。通过解决预算限制内的实际实施挑战,该研究旨在探索在视觉上受损的社区中使用双目摄像机在辅助技术中的可行性。立体视觉系统项目涉及对其技术和局限性的广泛研究,尤其是专注于双眼相机设置和机器学习。组装的立体声视觉设备利用开源计算机视觉库(OPENCV)进行对象识别和视频处理,启用距离计算(深度估计)。该项目具有双眼摄像机的持有人,并为用户提供了控制器形状的反馈系统。使用计算机辅助设计(CAD)软件实心边缘和三维(3D)打印的设计结合了振动电动机,以传达环境特性和障碍物接近用户。实施后,进行了实际测试,并评估了模块。项目的结果是针对双眼相机的完整设计,也是一个能够向用户提供信息的触觉反馈系统,从而使经过简单对象的导航能够。通过机器学习,该信息包括纸板箱的检测以及这些盒子的深度估计,这些盒子是根据校准和三角测量计算得出的。深度估计不会产生准确的结果,但是机器学习表现出很高的熟练程度,可以识别纸板箱。实际测试的结论表明,如果在该主题内完成了进一步的深入探索,则可以将双眼摄像机实施并发展为视觉障碍者的技术援助。

AI双目热像系统快速使用说明...
您现在可以继续按照指示使用 Internet Explorer 登录 Web 浏览器界面。完成初始摄像头配置并将摄像头的 IP 地址更改为 LAN 子网上可用的 IP 地址后,您可以将计算机重新连接到 LAN,并将其 IP 地址信息重置为您在步骤 3 中记录的原始设置。

双眼立体>的SGM算法介绍
•对两个图像中的相应像素的搜索如果进行了校准,则两个图像的搜索变得容易一些 - 这意味着,如果两个图像中的同一行中存在一对相应的像素。您从我的讲座24中知道,对于任何给定的像素(i,j)∈I,在另一个图像中必须在另一个图像中对其相应的像素进行搜索。,正如我在第24堂课中所解释的那样,

实时3D语义场景感知具有双眼视觉的自我中心机器人
摘要 - 在室内移动的同时,感知具有多个对象的三维(3D)场景对于基于视觉的移动配件至关重要,尤其是对于增强其操纵任务的尤其是。在这项工作中,我们为具有双眼视觉的自我中心机器人提供了实例分割,特征匹配和点集注册的端到端管道,并通过拟议的管道展示了机器人的抓地力。首先,我们为单视图3D语义场景分割设计了一个基于RGB图像的分割方法,并利用2D数据集中的常见对象类将3D点封装在对象实例的点云中,通过相应的深度映射。接下来,根据先前步骤中匹配的RGB图像中感兴趣的对象之间的匹配关键,提取了两个连续的点云的3D对应关系。此外,要意识到3D特征分布的空间变化,我们还根据使用内核密度估计(KDE)的估计分布(KDE)来称量每个3D点对,随后可以使稳健性具有较小的中心范围,同时求解点云之间的刚性转换。最后,我们在7-DOF双臂Baxter机器人上测试了我们提出的管道,并使用安装的Intel Realsense D435i RGB-D相机测试了我们的管道。结果表明我们的机器人可以在移动时分割感兴趣的对象,注册多个视图,并掌握目标对象。源代码可在https://github.com/mkhangg/semantic Scene感知上获得。