XiaoMi-AI文件搜索系统
World File Search SystemCombinatorial

组合 CRISPR 筛选的比较优化
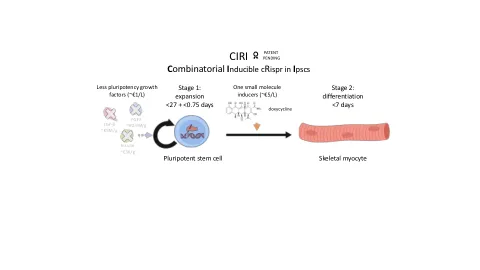
组合 CRISPR 技术已成为一种变革性方法,可系统地探测冗余基因对的遗传相互作用和依赖性。然而,不同的功能基因组工具在多路复用 sgRNA 方面的表现差异很大。在这里,我们生成并基准测试了十个不同的组合 CRISPR 文库,这些文库以同源物对为目标,以优化双基因敲除筛选。评估了由双化脓性链球菌 Cas9 (spCas9)、正交 spCas9 和金黄色葡萄球菌 (saCas9) 以及 Acidaminococcus 的增强型 Cas12a 组成的文库。我们证明了来自 spCas9 的替代 tracrRNA 序列的组合始终表现出优越的效应大小和 sgRNA 之间的位置平衡,这是一种强大的组合方法来分析多个基因的遗传相互作用。

组合药物发现计划库
CDDP Custom Informer (CCI) 药物库是从 MedChemExpress 生物活性集合中抽取的 4309 种生物活性分子。该库是通过从使用药物靶标和作用机制 (MoA) 注释生成的簇中选择代表性化学实体而构建的。该库以相对较少的分子提供高机制覆盖率。作为次要考虑因素,药物家族是从多代药物中选择出来的,这些药物家族涵盖了从临床前到批准使用的应用。因此,该库平衡了机制探针与转化应用。此外,该库以 384 孔板格式预先排列,富含药物 MoA,因此可以仅筛选最相关的部分并进一步提高筛选效率。该集合中的所有化合物均为 10mM,溶于 100% DMSO。美国国家癌症研究所批准的肿瘤学集合 X_2021

国际组合优化问题杂志...
摘要。构成工业 4.0 的新兴技术包括物联网和大数据。触觉界面已用于不同的行业,但显然它们并未与上述两种技术集成。这项工作旨在了解物联网、触觉界面和大数据在制造业中的当前用途。反过来,实施物联网平台的事实导致选择适应特定组织需求的架构。这就是为什么这项工作还试图描述文献中可用的物联网架构。最后,我们试图了解在机器学习支持的智能环境中结合物联网、触觉界面和大数据对制造业的潜在好处是什么。为了更好地理解,这项工作包括对该主题相关概念的描述,包括对监督学习算法的描述。最后,这项工作让我们为未来的研究打开了其他研究领域的大门。关键词:物联网、触觉界面、物联网架构、机器学习、监督算法、大数据、制造业。

组合优化的量子算法 - mediaTUM
首先,我要感谢我的博士导师兼主管 Robert König。他的指导、对科学和研究的热情和好奇心一直是我的灵感和动力源泉,我找不到比他更好的人和研究人员来指导我完成我的博士学位。接下来,我要感谢 M5 负责人 Michael Wolf,他成功地创造了一种美妙、高效、有趣的工作氛围,还要感谢我们的秘书 Silvia Schulz,她负责行政事务并与我们进行了多次愉快的交谈。由于这篇论文是一篇累积性论文,因此特色出版物至关重要,因此我要感谢我的合著者 Sergey Bravyi、Libor Caha、Robert König 和 Eugene Tang。与他们一起工作是我的荣幸,我很幸运能够向他们学习。总的来说,我在 M5 待过两次,所以我遇到了许多有趣、聪明的人,我很庆幸我可以称他们为同事和朋友。这些人包括我的“博士兄弟姐妹”Beatriz Cardoso Diaz、Shin Ho Choe、Margret Heinze 和 Stefan Huber,我的同事 Francesco Battistel、Libor Caha 和 Shangchun Yu,以及所有其他人:Zahra Baghali Khanian、Vjosa Blakaj、Andreas Bluhm、Ángela Capel Cuevas、Matthias Caro、Xavier Coiteux-Roy、Diana Conache、Pablo Costa Rico、Javier Cuesta、高丽、Paul Gondolf、Martina Gschwendtner、Lisa Hänggli、Markus Hasenöhrl、Anna-Lena Hashagen、Yifan Jia、李浩建、Tristan Malleville、Chokri Manai、Tim Möbus、Ion Nechita、Emilio Onorati、Michael Prähofer、Hjalmar Rall、Silke Rolles、Cambyse鲁泽、法尔津·萨利克、 Jeonghyeon Shin、Herbert Spohn、Daniel Stilck-França、Quirin Vogel、Simone Warzel 和 Amanda Young。他们让我在 M5 的时光成为一段美妙的体验,我将永远珍惜这段时光。我还要感谢我的博士导师 Andreas Johann,幸运的是,他从未干涉过任何不愉快的事情(根本没有这样的事情),院长办公室的 Lydia Weber 和 ISAM 协调员 Isabella Wiegand 都帮助我完成了博士论文的组织部分(尤其是在最后),还有我的治疗师 Martina Beck,她乐于助人、持续不断的支持给了我很大的帮助,我非常感谢她。我还要感谢我的好朋友 Rufat Badal、Bernhard Blieninger、Vincent Kar-bassioun、Maximilian Schiller、Dominik Stöger、Christoph Striegel 和 Andreas Wasmeier。最后,但并非最不重要的一点,我要感谢我的家人:我的父母 Brigitte 和 Helmut Kliesch、我的叔叔 Johann 和 Ludwig Rasch,以及我出色的姐妹 Elke、Marion 和 Christina Kliesch。


组合游行沿指数尾巴向下
新想法通常是现有商品或思想的组合,Romer(1993)和Weitzman(1998)强调了这一点。单独的文献强调了指数增长与帕累托分布之间的联系:Gabaix(1999)展示了指数增长如何产生帕累托分布,而Kortum(1997)则显示了帕累托分布如何产生指数级增长。但这提出了一个“鸡肉和鸡蛋”问题:哪个是第一个是指数级的增长或帕累托分布?,无论如何,Romer和Weitzman的见解发生了什么,Combinatorics应该很重要?本文通过证明从标准薄尾分配的抽取数量的组合增长会导致指数级经济增长来回答这些问题;无需帕累托假设。更一般地,它提供了一个定理,将最大极端值的行为与抽奖数和尾巴的形状联系起来,以进行任何连续的概率分布。

量子随机函数的组合方法
伪随机函数 (PRF) 是现代密码学的基本组成部分之一。Goldreich、Goldwasser 和 Micali 在开创性著作 [ 13 ] 中引入了 PRF,回答了如何构建一个与随机函数难以区分的函数的问题。粗略地说,PRF 可以保证没有任何有效算法能够通过 oracle 访问这样的函数而将其与真正的随机函数区分开来。事实证明,PRF 是密码原语(如分组密码和消息认证码)设计中的宝贵工具,而且现在已成为一个很好理解的对象:继 [ 13 ] 基于树的构造之后,PRF 已从伪随机合成器 [ 19 ] 和直接从许多难题 [ 20 、 21 、 22 、 11 、 18 、 7 、 2 ] 构建而成。然而,当考虑更精细的量子设置时,对 PRF 硬度的研究仍处于起步阶段。在深入研究这一原语的细节之前,需要进行一些澄清,因为可以用两种方式定义 PRF 的量子安全性:

