XiaoMi-AI文件搜索系统
World File Search SystemSNN

一种用于实现随机二进制尖峰时间相关可塑性的 CMOS-忆阻器混合系统
本文介绍了一个完全实验性的混合系统,其中使用定制的高阻态忆阻器和采用 180 nm CMOS 技术制造的模拟 CMOS 神经元组装了一个 4 × 4 忆阻交叉脉冲神经网络 (SNN)。定制忆阻器使用 NMOS 选择晶体管,该晶体管位于第二个 180 nm CMOS 芯片上。一个缺点是忆阻器的工作电流在微安范围内,而模拟 CMOS 神经元可能需要的工作电流在皮安范围内。一种可能的解决方案是使用紧凑电路将忆阻器域电流缩小到模拟 CMOS 神经元域电流至少 5-6 个数量级。在这里,我们建议使用基于 MOS 阶梯的片上紧凑电流分配器电路,将电流大幅衰减 5 个数量级以上。每个神经元之前都添加了这个电路。本文介绍了使用 4 × 4 1T1R 突触交叉开关和四个突触后 CMOS 电路的 SNN 电路的正确实验操作,每个电路都有一个 5 个十进制电流衰减器和一个积分激发神经元。它还演示了使用此小型系统进行的一次性赢家通吃训练和随机二进制脉冲时间依赖可塑性学习。

一种生物学上可信的脉冲神经网络,用于解码海马和运动前皮层的运动学
摘要 — 本研究提出了一种脉冲神经网络,用于根据神经数据预测运动学,从而实现准确且节能的脑机接口。脑机接口是一种解释神经信号的技术系统,可让运动障碍患者控制假肢。脉冲神经网络具有低功耗和与生物神经结构非常相似的特点,因此有可能改进脑机接口技术。本研究中的 SNN 使用泄漏积分和激发模型来模拟神经元的行为,并使用局部学习方法进行学习,该方法使用替代梯度来学习网络参数。该网络实现了一种新颖的连续时间输出编码方案,允许基于回归的学习。SNN 是在从灵长类动物运动前皮层和大鼠海马记录的神经和运动数据上进行离线训练和测试的。该模型通过寻找预测运动数据与真实运动数据之间的相关性来评估,运动前皮层记录的峰值皮尔逊相关系数达到 0.77,海马体记录的峰值皮尔逊相关系数达到 0.80。该模型的准确性与卡尔曼滤波解码器和 LSTM 网络以及使用反向传播训练的脉冲神经网络进行了对比,以比较局部学习的效果。

可重构神经形态系统的低延迟分层路由
使用现场可编程门阵列 (FPGA) 实现可重构硬件加速器以进行脉冲神经网络 (SNN) 模拟是一项有前途且有吸引力的研究,因为大规模并行性可以提高执行速度。对于大规模 SNN 模拟,需要大量 FPGA。然而,FPGA 间通信瓶颈会导致拥塞、数据丢失和延迟效率低下。在这项工作中,我们为多 FPGA 采用了基于树的分层互连架构。这种架构是可扩展的,因为可以将新分支添加到树中,从而保持恒定的本地带宽。基于树的方法与线性片上网络 (NoC) 形成对比,在片上网络 (NoC) 中,拥塞可能由众多连接引起。我们提出了一种路由架构,该架构通过采用随机仲裁引入仲裁器机制,考虑先进先出 (FIFO) 缓冲区的数据级队列。该机制有效地减少了由 FIFO 拥塞引起的瓶颈,从而改善了整体延迟。结果显示了为延迟性能分析而收集的测量数据。我们将使用我们提出的随机路由方案的设计性能与传统的循环架构进行了比较。结果表明,与循环仲裁器相比,随机仲裁器实现了更低的最坏情况延迟和更高的整体性能。

用于神经形态计算的具有易失性阈值开关行为的氧化还原忆阻器
脉冲神经网络 (SNN) 的设计灵感来源于人类大脑,它是使用集成系统中的传统或新兴电子设备在硬件上实现高效、低成本和鲁棒的神经形态计算的最强大平台之一。在硬件实现中,人工脉冲神经元的构建是构建整个系统的基础。然而,随着摩尔定律的放缓,传统的互补金属氧化物半导体 (CMOS) 技术逐渐衰落,无法满足日益增长的神经形态计算需求。此外,由于 CMOS 器件的生物可行性有限,现有的人工神经元电路非常复杂。具有易失性阈值开关 (TS) 行为和丰富动态的忆阻器是超越 CMOS 技术模拟生物脉冲神经元并构建高效神经形态系统的有希望的候选者。本文回顾了有关 SNN 基础知识的最新进展。此外,我们回顾了基于 TS 忆阻器的神经元及其系统的实现,并指出了系统演示中从器件到电路需要进一步考虑的挑战。我们希望这篇综述可以为未来基于忆阻器的神经形态计算的发展提供线索和帮助。

原子位移使非共线反铁磁体中异常霍尔效应的观察成为可能
具有非共线自旋结构的反铁磁体表现出各种特性,使其对自旋电子器件具有吸引力。其中一些最有趣的例子是尽管磁化可以忽略不计,但仍然表现出异常霍尔效应,以及具有不寻常自旋极化方向的自旋霍尔效应。然而,只有当样品主要处于单个反铁磁畴状态时,才能观察到这些效应。这只有当补偿自旋结构受到扰动并由于自旋倾斜而显示出弱矩时才能实现,从而允许外部畴控制。在立方非共线反铁磁体的薄膜中,这种不平衡以前被认为需要由基板应变引起的四方畸变。本文表明,在 Mn 3 SnN 和 Mn 3 GaN 中,自旋倾斜是由于磁性锰原子远离高对称位置的大量位移导致结构对称性降低。当仅探测晶格度量时,这些位移在 X 射线衍射中仍然隐藏,需要测量大量散射矢量才能解析局部原子位置。在 Mn 3 SnN 中,诱导净矩使得能够观察到具有不同寻常温度依赖性的异常霍尔效应,据推测这是由于 kagome 平面内类似块体的温度依赖性相干自旋旋转所致。

高级材料-2023 -Rimmler-原子...
具有非类线性自旋结构的抗铁磁体显示出各种特性,使它们对自旋装置有吸引力。尽管磁化可忽略不计,但一些最有趣的例子是一个异常的大厅效应,并且具有异常的自旋极化方向的旋转大厅的作用。但是,只有在将样品主要设置为单个抗铁磁域状态时,才能观察到这些效应。只有在扰动补偿的自旋结构并由于旋转倾斜而显示较弱的力矩时才能实现这一目标,从而允许外部域控制。在立方非连续性抗铁磁铁的薄膜中,以前认为这种失衡需要底物应变引起的四方畸变。在这里,显示在Mn 3 snn和Mn 3 gan中,旋转倾斜是由于结构对称性降低引起的磁锰原子诱导的诱导,远离高对称位置。仅当仅探测晶格度量时,这些位移仍隐藏在X射线差异中,并且需要测量大量散射向量以解决局部原子位置。在Mn 3 SNN中,诱导的净力矩可以与异常的温度依赖性观察到异常的大厅的作用,这是由kagome平面内的散装温度依赖性相干旋转旋转引起的。

PowerPoint海报模板
交易异常仍然是一个问题。特别是对于贸易融资,损益可能取决于它。为证明量子计算将有助于交易异常检测的概念,该项目研究了在暹罗神经网络(SNN)架构上操作的量子电路的潜力,从而检测到交易中的异常数据喜欢数据。这项研究的目的是开始探索量子机器学习如何改善贸易融资金融交易的异常检测。

脑启发计算 - NSF-PAR
摘要 — 本次特别会议论文的目标是介绍和讨论不同的突破性技术以及新颖的架构,以及它们如何共同重塑人工智能的未来。我们的目标是全面概述受脑启发计算的最新进展,以及当使用超 CMOS 设备的新兴技术与超越冯诺依曼架构的新型计算范式相结合时,如何实现后者。我们讨论了铁电场效应晶体管 (FeFET)、相变存储器 (PCM) 和电阻式 RAM (ReRAM) 等不同的新兴技术,展示了它们在构建受自然启发的神经形态计算架构方面的良好能力。此外,本特别会议论文还讨论了各种新概念,如内存逻辑 (LIM)、内存处理 (PIM) 和脉冲神经网络 (SNN),以探索超越冯诺依曼计算对加速深度学习的深远影响。最后,将脑启发计算的最新趋势总结为算法、技术和应用驱动的创新,以比较不同的 PIM 架构。索引词 —FeFET、PCM、ReRAM、光子、神经形态、DNN、SNN、内存处理、新兴技术
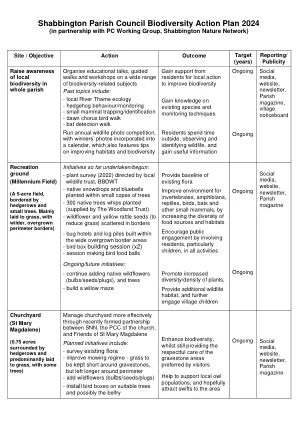
Shabbington教区理事会生物多样性行动计划2024
在可能的情况下与截至迄今为止的相互有益的举措互动并协助: - 为将安装在乡村边缘农场的废弃巴恩(Barn of Village -Edge Farm)中安装在乡村边缘农场的Barn Barn的确保协议,由Borg当地教区议会和其他环境团体的成员和其他环境团体和其他环境团体的成员 - 交换奖励的想法,并提供了奖励年轻人,以奖励年轻人,以奖励年轻人 - 在自然界中提供了杜克(Edin)的机会 - 技术任务,例如河水测试在可能的情况下与截至迄今为止的相互有益的举措互动并协助: - 为将安装在乡村边缘农场的废弃巴恩(Barn of Village -Edge Farm)中安装在乡村边缘农场的Barn Barn的确保协议,由Borg当地教区议会和其他环境团体的成员和其他环境团体和其他环境团体的成员 - 交换奖励的想法,并提供了奖励年轻人,以奖励年轻人,以奖励年轻人 - 在自然界中提供了杜克(Edin)的机会 - 技术任务,例如河水测试

神经形态入门套件的披露
神经形态计算是一种受大脑启发的计算方法。神经形态计算的主要构造是脉冲神经网络 (SNN),许多资料对此进行了解释 [20]、[24]。我们使用术语“神经处理器”来定义一种计算设备,在该设备上可以加载脉冲神经网络,然后将输入脉冲暂时应用于特定的输入神经元。神经处理器处理脉冲并运行 SNN,在整个网络中传播脉冲。有指定的输出神经元,可以从外部读取脉冲。有许多神经处理器模拟器 [3]、[5]、[10] 和硬件项目 [1]、[4]、[8]、[24]。然而,大多数硬件项目都是商业性的,或者由研究项目以各个研究小组独有的方式运行。我们这项工作的目的是提供一种低成本、灵活的硬件套件,研究人员可以使用它来探索神经形态计算。具体来说,我们的目标是让该套件能够实现一种简单且廉价的机制,用于开发由神经处理器驱动的物理应用。我们的灵感之一来自代尔夫特大学的一个项目,其中的作者实现了一个神经形态 PID 控制器,用于调整 MAV 的高度 [28]。作者显然需要一个小型、轻便、自封装的系统,用于将传感器输入转换为脉冲,将这些脉冲发送到神经处理器,然后解释输出脉冲。我们设计了该套件用于类似这样的用例。在本文的后续部分中,我们将描述套件的组件、它们的组成、示例套件和物理应用。