XiaoMi-AI文件搜索系统
World File Search System匹配的
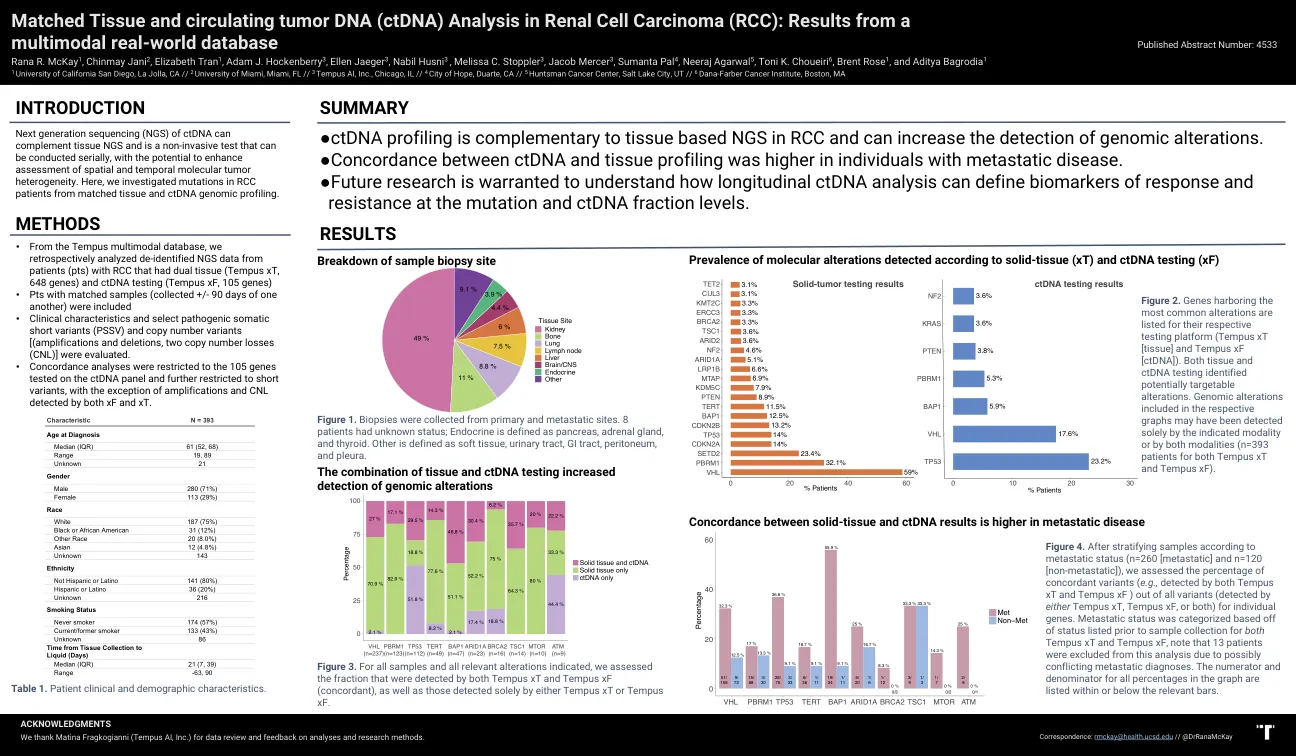
肾细胞癌(RCC)中匹配的组织和循环肿瘤DNA(CTDNA)分析:来自多模式现实世界数据库
结果•从tempus多模式数据库中,我们回顾了带有双组织(tempus XT,648个基因)和ctDNA测试的RCC的患者(PTS)的去识别的NGS数据(PTS)(tempus XF,105个基因)•PTS•PTS clunicatiental and clintical Spellicatient contricatient•colletical Spellicatient•colletical contericatients•另一种天数•另一位 +90天 +/-90天,评估了简短变体(PSSV)和拷贝数变体[(放大和删除,两个拷贝数损失(CNL)]。•一致性分析仅限于在ctDNA面板上测试的105个基因,并进一步限于短变体,除了放大和XF和XT检测到的CNL外。

体内近红外光谱谱图将阿尔茨海默氏病的受试者与年龄匹配的对照区分开
摘要。背景:诸如阿尔茨海默氏病(AD)的PET和MRI AID临床评估之类的医学成像方法。便宜,技术要求较低,并且需要更广泛的可部署技术来扩大客观筛查以进行诊断,治疗和研究。我们先前在体外报道了脑组织近红外光谱(NIR),表明有可能满足这种需求的潜力。目标:通过匹配对照组的临床,临床,NIR Invivo CandistinguishAdpatients,临床,NIR Invivo CandistryishAdpatients,并显示了NIR作为临床筛查的潜力和监测治疗性有效性的潜力。方法:在体内获取NIR光谱。研究了三组:尸检确认AD,对照和轻度认知障碍(MCI)。使用强度归一化光谱的第一个衍生物的特征选择方法用于发现最能区分“ ad-alone”(即没有其他显着神经病理学)的光谱区域。然后将该方法应用于其他尸检确认的AD病例和临床诊断的MCI病例。结果:大约860和895 nm的两个区域将AD患者与对照组完全分开,并根据损伤程度区分MCI受试者。895 nm功能在将MCI受试者与对照组分开(权重:1.3)方面更为重要。 860 nm功能对于区分MCI和AD(重量比率:8.2)更为重要。结论:这些结果构成了近红外光谱可以检测和分类患病和正常人脑的概念的证明。需要进行临床试验来确定这两个特征是否可以跟踪疾病进展并监测潜在的治疗干预措施。

OPRA非播放使用声明
使用数据使用数据的组织3非显示功能必须计算每个“平台”,该“平台”在非显示基础上使用数据。“平台”是一个可以内部匹配的买卖订单的平台。匹配的买卖订单包括代表数据收件人自己和/或代表其客户匹配的客户订单。例如,一个使用OPRA数据以操作ATS的组织以及不注册为ATS的经纪人交叉系统的目的,需要支付两种3类的3类非显示使用费用。

可搜索的摘要文档
完全动态的匹配问题涉及有效地维持在图形上进行边缘插入和删除的近乎最佳匹配。尽管出现了重要的效率,但设计高效的完全动态匹配算法的目的仍然难以捉摸。获得更快的算法的有希望的自然途径是使匹配的稀疏器成为主导,即稀疏子图,在原始图的每个引起的子图中都可以保留大致匹配的较大匹配。这一措施的成功取决于两个挑战的积极分辨率:显示存在稀疏匹配的稀疏器的存在,并设计了用于构造它们的有效算法。事实证明,第一个挑战是与确定Ruzsa-Szemer´eDi(RS)图的密度的问题密切相关的,即,可以将边缘分为诱导的线性大小匹配的图形。但是,即使对RS图密度问题的乐观分辨率仍然会留下第二个挑战。令人兴奋的洞察力突出了RS图的放松概念,称为有序RS图,令人惊讶地使上面的两个挑战都折叠成有关此类图的密度的单个组合问题。本演讲将探讨这些想法之间的迷人相互作用,并将展示这种相互作用如何导致完全动态匹配的条件梦想结果。

模仿机器人学:调查 - 虹膜
交互式模仿学习(IIL)是模仿学习(IL)的一个分支,在机器人执行过程中,间歇性地提供了人类反馈,从而可以在线改善机器人的行为。近年来,IIL越来越开始开拓自己的空间,作为解决复杂机器人任务的有前途的数据驱动替代方案。IIL的优势是双重的,1)它是有效的,因为人类的反馈将机器人直接引导到了改善行为(与增强学习(RL)相反(RL),必须通过试用和错误发现行为(必须通过试用和错误发现),而2),并且2)是强大的,因为它是强大的,因为分配者和教师的分配量直接在教师身上是匹配的,并且在教师中匹配的范围是在范围内逐渐匹配的,并且在教师中匹配的范围是在范围内的指导,而逐渐匹配的是,教师的自我反射是及格的, o line Ile IL方法,例如行为克隆)。尽管有机会,但文献中的术语,结构和适用性尚不清楚,也尚未确定,从而减慢了其发展,因此,研究了创新的表述和发现。在本文中,我们试图通过对统一和结构的领域进行调查来促进新从业人员的IIL研究和较低的入境障碍。此外,我们旨在提高人们对其潜力,已完成的工作以及仍在开放的研究问题的认识。

模拟与数字:电路实现的比较...
传播频谱通讯系统的匹配的过滤器或相关器块占据了接收器的位置,仅在模拟RF-to-Base带或RF-to-to-if-to-if-if downversion电路中均位于数字数据删除电路之前。因此,可以通过数字或模拟电路技术实现匹配的过滤器。本文使用功率效率(作为信号完整性,滤波器大小,操作频率和技术缩放的函数)分析并比较了可编程par-allel匹配的滤波器的数字和模拟实现 - 作为比较的主要指标。提出了一种方法,并给出了指示多维设计空间数字电路比模拟效率更有效的结果,反之亦然。

基于谐振电感耦合和阻抗匹配的微型机器人无线电力传输框架 Kin Yun Lum、Jyi-Shyan Chow、Kah Haur Y
微型机器人属于微型机器人领域,尺寸为几厘米甚至几毫米。传统上,这些小型机器人通常由电池供电。电池会占用大量空间并导致系统笨重。将储能组件与机器人本身隔离是进一步缩小机器人尺寸的良好替代方案。这可以通过结合无线电力传输 (WPT) 技术来实现。然而,小型 WPT 的研究通常报告效率较低。本文的目的是通过采用谐振电感耦合和阻抗匹配技术为微型机器人提供一种高效的无线电力传输框架。将讨论理论和设计过程。然后,进行了一个简单的原型实验来验证提出的框架。结果表明,在 0.5 厘米的传输距离上实现了 35% 的传输效率。该框架还成功为 4 瓦微型机器人原型供电,传输效率约为 16%,其接收线圈位于发射线圈上方 3.5 厘米处。

灭活的共同199疫苗接种对女性卵巢储备的影响:倾向得分匹配的回顾性队列研究
1江西孕产妇和儿童健康医院,国家临床研究中心江西分公司,妇产科和妇科研究中心,南昌医学院,中国北昌,2皇后医学系,皇后玛丽临床医学院,北昌大学,北昌大学,中国,医学,医学,医学,纽约州,曾经是妇产科,中国,江西孕产妇和儿童健康医院4病理学系,国家临床临床研究中心,北昌医学院,北昌,中国北昌医学院,江西孕产妇和儿童健康医院的妇产科和妇产科5江西省妇女生殖健康实验室,江西孕产妇和儿童健康医院,江西分公司国家妇产科和妇科研究中心,北昌医学院,中国北昌

有效的端到端视觉定位,用于脱钩的BEV神经匹配
摘要 - 准确的定位在高级自主驾驶系统中起重要作用。传统地图匹配的本地化方法通过具有传感器观测值的明确匹配的地图元素来解决姿势,通常对感知噪声敏感,因此需要昂贵的超级参数调整。在本文中,我们提出了一个端到端定位神经网络,该神经网络直接估计车辆从周围图像中构成,而没有与HD图明确匹配的感知结果。为确保效率和可预性能力,提出了一个基于BEV神经匹配的姿势求解器,估计在基于可区分的采样匹配模块中估计姿势。此外,通过将每个姿势DOF影响的特征表示形式解耦来大大降低采样空间。实验结果表明,所提出的网络能够执行分解器水平的定位,平均绝对误差为0.19m,0.13m和0.39◦在纵向,横向位置和偏航角度,同时表现出68.8%的推理记忆使用率降低了68.8%。

有效的端到端视觉定位,用于脱钩的BEV神经匹配
摘要 - 准确的定位在高级自主驾驶系统中起重要作用。传统地图匹配的本地化方法通过具有传感器观测值的明确匹配的地图元素来解决姿势,通常对感知噪声敏感,因此需要昂贵的超级参数调整。在本文中,我们提出了一个端到端定位神经网络,该神经网络直接估计车辆从周围图像中构成,而没有与HD图明确匹配的感知结果。为确保效率和可预性能力,提出了一个基于BEV神经匹配的姿势求解器,估计在基于可区分的采样匹配模块中估计姿势。此外,通过将每个姿势DOF影响的特征表示形式解耦来大大降低采样空间。实验结果表明,所提出的网络能够执行分解器水平的定位,平均绝对误差为0.19m,0.13m和0.39◦在纵向,横向位置和偏航角度,同时表现出68.8%的推理记忆使用率降低了68.8%。