
机构名称:
¥ 2.0
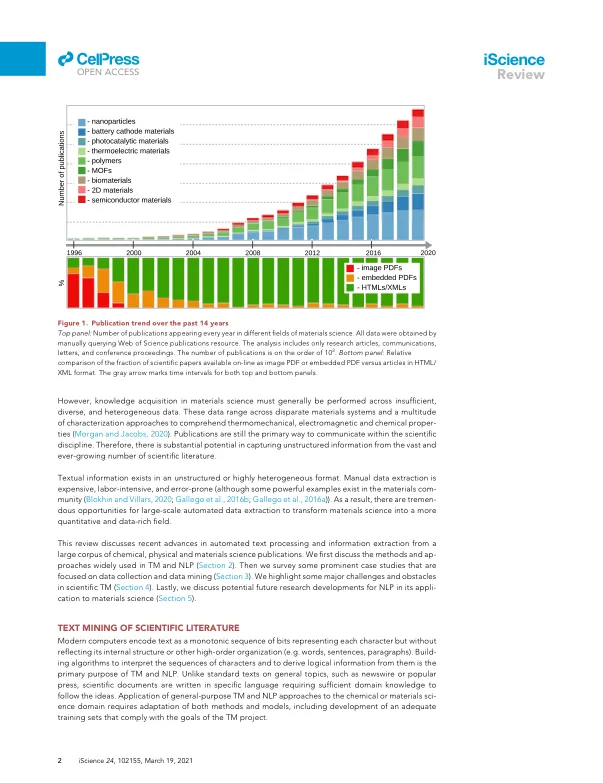
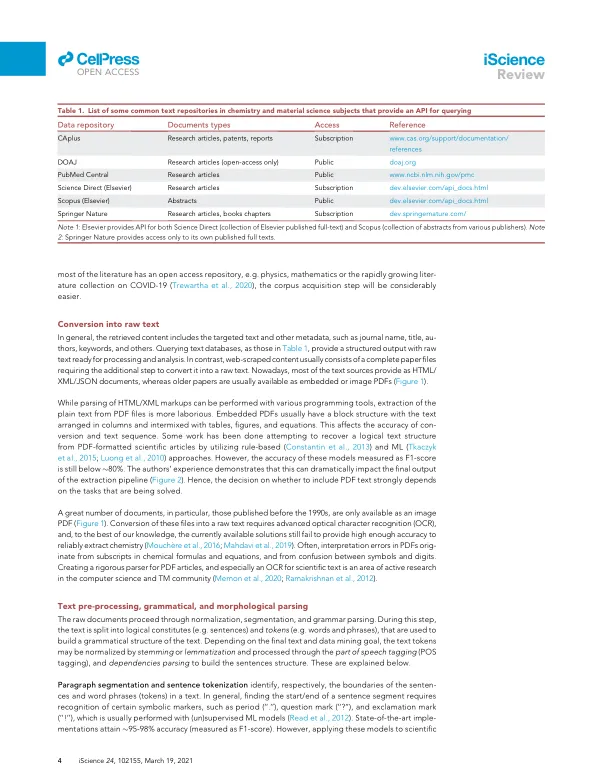
摘要 研究出版物是科学知识的主要宝库。然而,它们的非结构化和高度异构的格式对其中包含的信息的大规模分析造成了重大障碍。自然语言处理(NLP)的最新进展提供了各种工具,用于从非结构化文本中提取高质量的信息。这些工具主要针对非技术文本进行训练,当应用于涉及特定技术术语的科学文本时,很难产生准确的结果。在过去的几年里,人们在生物医学和生物化学出版物的信息检索方面做出了重大努力。对于材料科学,文本挖掘(TM)方法仍处于发展初期。在这篇综述中,我们调查了在材料科学领域创建和应用 TM 和 NLP 方法的最新进展。这篇综述针对广大研究人员,他们旨在学习 TM 基础知识在材料科学出版物中的应用。
文本挖掘在材料研究中的机遇与挑战
主要关键词



相关文件推荐





























