
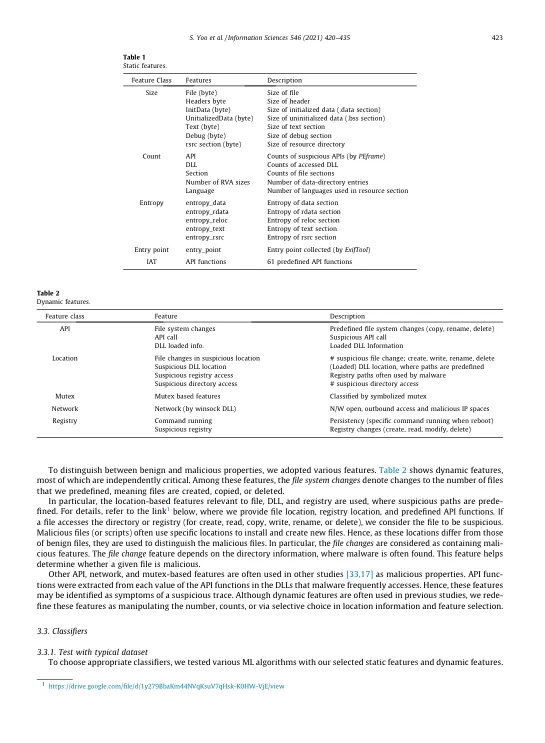
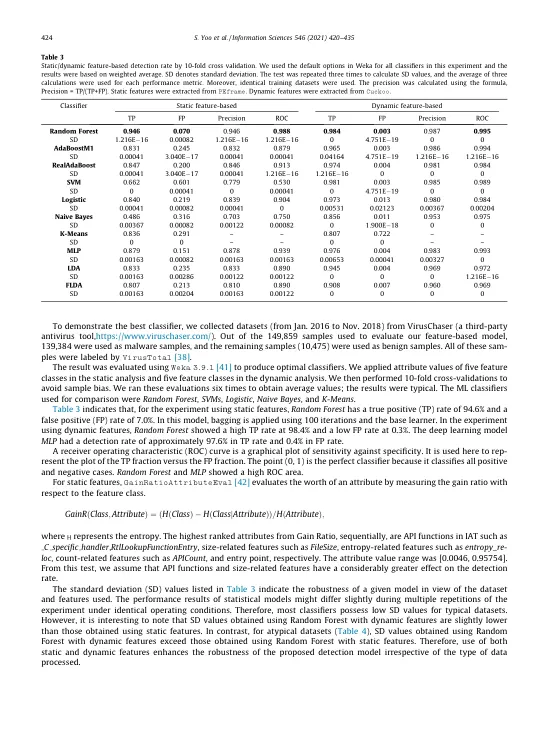
机构名称:
¥ 1.0
互联网的极度分散的架构使得恶意软件得以传播,对开发针对此类恶意软件传播的防御措施提出了重大挑战。虽然基于机器学习的恶意软件检测模型可以改进应对此问题的方法,但它们的检测率会根据其特征和分类方法而有所不同。尽管使用了适当的训练数据集,但用于恶意软件检测的单一机器学习方法的有效性会根据其分类器的适用性而有所不同。一些分类器在恶意训练数据集上的检测率很高,但在良性训练数据集上的检测率很低,并且误报率特别依赖于使用适当的分类器。在本文中,我们提出了一种基于机器学习的混合决策模型,该模型可以实现高检测率和低误报率。该混合模型结合了随机森林和深度学习模型,分别使用 12 个隐藏层来确定恶意软件和良性文件。该模型还包括某些拟议的投票规则以做出最终决策。在涉及 6,395 个非典型样本的实验中,该混合决策模型的检测率(85.1%,标准差为 0.006)高于没有投票规则的先前模型(65.5%)。2020 作者。由 Elsevier Inc. 出版。这是一篇根据 CC BY-NC-ND 许可协议开放获取的文章( http://creativecommons.org/licenses/by-nc-nd/4.0/ )。
ai-hydra.pdf - 网络安全系统研究实验室
主要关键词



相关文件推荐



























