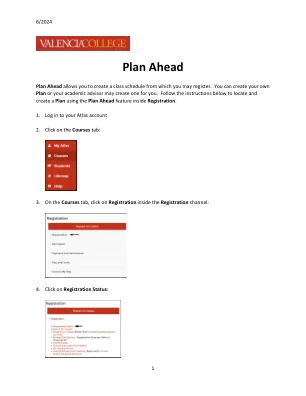
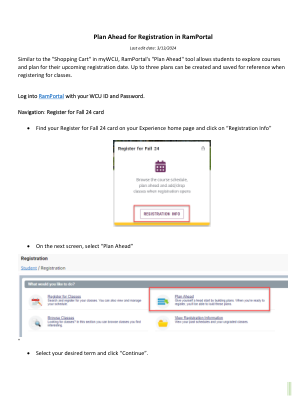
机构名称:
¥ 1.0
尽管上下文化的语言模型最近在各种NLP任务上取得了成功,但语言模型本身仍无法捕获长长的多句文档的文本共同(例如,段落)。人类经常就发言之前就何种方式以及如何发言做出结构性决定。通过这种高级决策和以连贯的方式构建文本的指导性实现被称为计划过程。模型可以在哪里学习这样的高级相干?段落本身包含在这项工作中称为自upervision的各种形式的归纳相干信号,例如句子顺序,局部关键字,修辞结构等。以此为动机,这项工作为新的段落完成任务p ar -c om;在图形中预测蒙版的句子。但是,该任务遭受了预测和选择相对于给定上下文的适当局部内容。为了解决这个问题,我们提出了一个自我监督的文本计划,该计划可以预测首先说出的内容(内容预测),然后使用预测的内容指导验证的语言模型(表面实现)。SSPlanner在自动和人类评估中的段落完成任务上的基线生成模型优于基线生成模型。我们还发现,名词和动词类型的关键字的组合是最有效的内容选择。提供了更多内容关键字,总体发电质量也会提高。
提前计划:段落完成任务的自我监督文本计划
主要关键词





相关文件推荐