
机构名称:
¥ 2.0
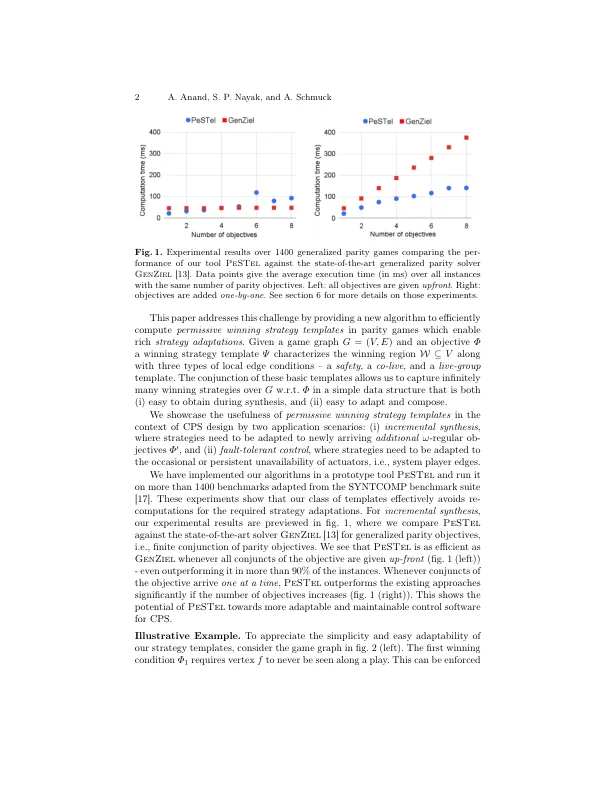
摘要。我们提出了一种新的方法,可以在两人游戏中计算有限的胜利策略,这些策略具有ω的冠军条件。给定游戏图G和平均赢得条件φ,我们计算了一个获胜的策略模板ψ,该模板ψ在简明的数据结构中收集了目标φ的胜利策略。We use this new representation of sets of winning strategies to tackle two problems arising from applications of two-player games in the context of cyber-physical system design – (i) incremental synthesis , i.e., adapt- ing strategies to newly arriving, additional ω -regular objectives Φ ′ , and (ii) fault-tolerant control , i.e., adapting strategies to the occasional or persistent执行器不可用。我们的策略模板的主要特征(我们用于解决这些挑战)是它们的简单可计算性,适应性和组成性。对于增量综合,我们从经验上表明,如果添加的规格数量增加,我们的技术表明,我们的技术大大优于现有方法。虽然我们的方法尚未完成,但我们的原型实现将在所有1400个基准中返回完整的获胜区域,即在实践中处理大型问题类别。
综合宽松的获胜策略模板
主要关键词




相关文件推荐





























