机构名称:
¥ 1.0
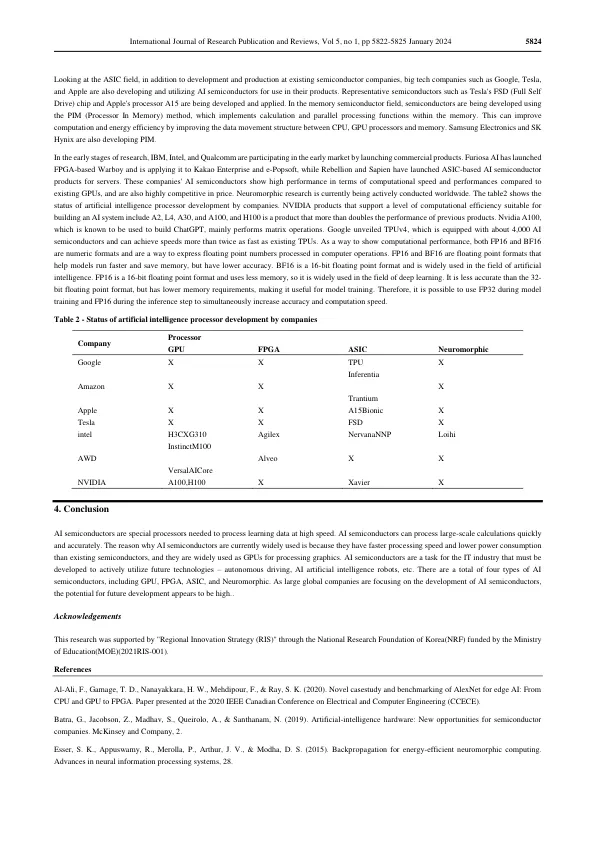
大多数人工智能算法在现有的计算系统上运行,例如中央处理单元(CPU),图形处理单元(GPU)和现场可编程可编程的门阵列(FPGAS)。(Batra,Jacobson,Madhav,Queirolo和Santhanam,2019年; Viswanathan,2020年),也正在开发用于加速机器学习的数字类型或模拟数字混合信号类型的应用特定的集成电路(ASIC)。然而,随着摩尔法律方法的扩展极限,通过现有扩展可以实现的性能和功率效率正在下降。需要一个特殊的处理器来在短时间内接受和处理学习数据,而该处理器是“ AI半导体”。AI半导体是专门针对效率的非内存半导体,以超高速度和超功率实施AI服务所需的大规模计算。AI半导体对应于核心大脑,学习数据并从中得出推断的结果。(Al-Ali,Gamage,Nanayakkara,Mehdipour,&Ray,2020; Batra等,2019; Esser,Appuswamy,Merolla,Arthur,&Modha,2015年)CPU是处理计算机所有输入,输出和命令处理的计算机的大脑。但是,对于需要大规模并行处理操作的AI,串行处理数据的CPU并未优化。为了克服这一限制,GPU已成为替代方案。gpu是针对3D游戏等高端图形处理开发的,但具有并行处理数据的特征,使其成为AI半导体之一。
人工光合作用:可再生能源的来源-IJRPR
主要关键词



相关文件推荐