机构名称:
¥ 2.0
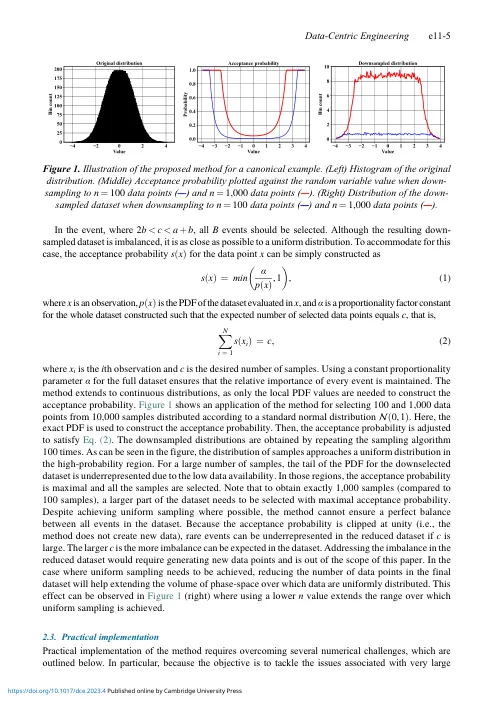
计算和实验能力的提高正在迅速增加日常生成的科学数据量。在受内存和计算强度限制的应用中,过大的数据集可能会阻碍科学发现,因此数据缩减成为数据驱动方法的关键组成部分。数据集在两个方向上增长:数据点的数量和维数。降维通常旨在在低维空间中描述每个数据样本,而这里的重点是减少数据点的数量。提出了一种选择数据点的策略,使它们均匀地跨越数据的相空间。所提出的算法依赖于估计数据的概率图并使用它来构建接受概率。当仅使用数据集的一小部分来构建概率图时,使用迭代方法来准确估计稀有数据点的概率。不是对相空间进行分组来估计概率图,而是用正则化流来近似其函数形式。因此,该方法自然可以扩展到高维数据集。所提出的框架被证明是在拥有大量数据时实现数据高效机器学习的可行途径。
利用迭代正则化流进行相空间均匀数据选择
主要关键词




相关文件推荐