
机构名称:
¥ 1.0
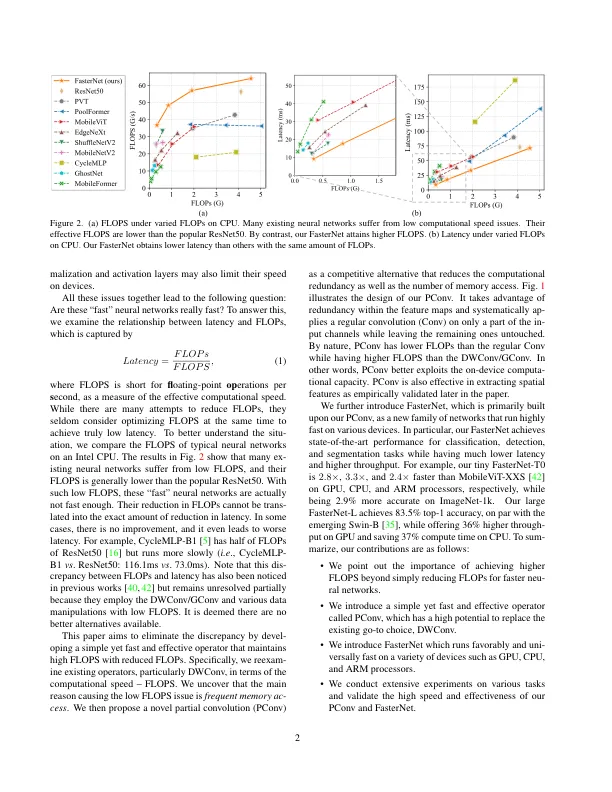
为设计快速神经网络,许多作品一直集中在减少浮点操作数量(FLOPS)的数量上。我们观察到,这种减少的失败并不一定会导致潜伏期的相似水平。这主要源于每秒效率低下的低浮点操作(拖鞋)。为了实现更快的网络,我们重新审视了流行的运营商,并认为如此低的拖鞋主要是由于操作员的频繁访问,尤其是深度方向的访问。因此,我们提出了一种新型的部分卷积(PCONV),该卷积通过同时减少冗余计算和内存访问来提取空间特征。在我们的PCONV上,我们进一步构建了一个新的神经网络家族Fasternet,它的运行速度比在各种设备上的其他设备都高得多,而没有损害各种视觉任务的准确性。,例如,在Imagenet-1K上,我们的Tiny Forpernet-T0为2。8×,3。 3×和2。 4×比GPU,CPU和ARM处理器上的移动电视-XX快速快,同时准确2.9%。 与新兴的SWIN-B相当,我们的大型fornet-l可以达到令人印象深刻的83.5%Top-1精确度,而GPU上的Incrence吞吐量提高了36%,并节省了CPU上的37%的计算时间。 代码可在https:// github上找到。 com/jierunchen/fasternet。8×,3。3×和2。4×比GPU,CPU和ARM处理器上的移动电视-XX快速快,同时准确2.9%。与新兴的SWIN-B相当,我们的大型fornet-l可以达到令人印象深刻的83.5%Top-1精确度,而GPU上的Incrence吞吐量提高了36%,并节省了CPU上的37%的计算时间。代码可在https:// github上找到。com/jierunchen/fasternet。
追逐更高的拖鞋以获取更快的神经网络
主要关键词




相关文件推荐





























