机构名称:
¥ 1.0
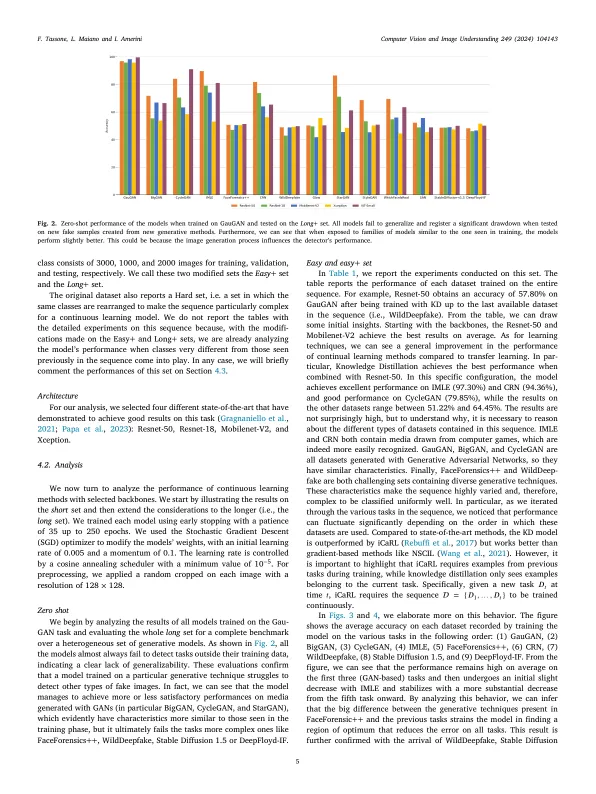
生成技术在这些技术的炒作驱动的驱动下继续以高度高的速度发展。这种快速的进步严重限制了DeepFake探测器的应用,尽管科学界做出了许多努力,但仍在努力实现对不断变化的内容的足够强大的性能。为了解决这些局限性,在本文中,我们提出了对两种连续学习技术的分析,以一系列短序列的假媒体进行分析。这两个序列都包括来自gan,计算机图形技术和未知来源的复杂和异质范围的深击(生成的图像和视频)。我们的实验表明,持续学习对于减轻对普遍性的需求可能很重要。实际上,我们表明,尽管有一些局限性,但持续的学习方法有助于在整个训练序列中保持良好的表现。为了使这些技术以一种足够健壮的方式工作,但是,序列中的任务必须具有相似性。实际上,根据我们的实验,任务的顺序和相似性会随着时间的推移影响模型的性能。为了解决这个问题,我们表明可以根据其相似性分组任务。这种小措施即使在更长的序列中也可以显着改善。这个结果表明,持续的技术可以与最有前途的检测方法结合使用,从而使它们能够赶上最新的生成技术。除此之外,我们还概述了如何将这种学习方法集成到持续集成和连续部署(CI/CD)中的深层检测管道中。这使您可以跟踪不同的资金,例如社交网络,新的生成工具或第三方数据集,并通过连续学习的集成,可以持续维护检测器。
连续的假媒体检测
主要关键词




相关文件推荐