
机构名称:
¥ 1.0
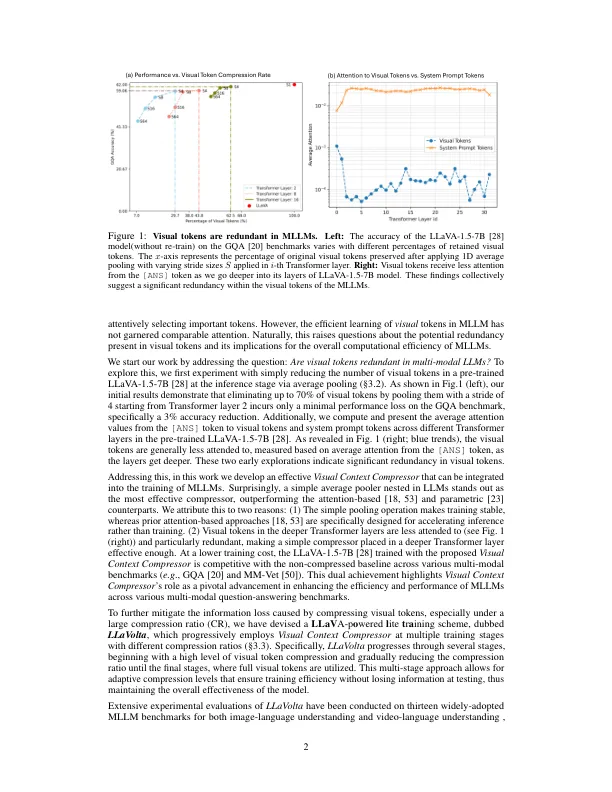
尽管在大型语言模型(LLMS)的文本嵌入的压缩表示中已取得了重大进步,但多模式LLMS(MLLMS)中视觉令牌的压缩仍然很大程度上被忽略了。在这项工作中,我们介绍了有关在这些模型中有关视觉令牌和有效培训的冗余分析的研究。我们的初始实验表明,在测试阶段消除多达70%的视觉令牌,仅通过平均池,仅导致在视觉问题上降低3%的降低3%,从而回答GQA基准上的准确性,这表明在视觉上下文中有显着的冗余。解决此问题,我们介绍了视觉上下文压缩机,这减少了视觉令牌的数量,以提高训练和推理效率而不牺牲性能。为了最大程度地减少视觉令牌压缩而导致的信息损失,同时保持训练效率,我们将Llavolta作为轻巧和分期的训练方案开发,该方案结合了阶段的视觉上下文压缩,以逐步压缩视觉令牌从严重压缩到在训练过程中的轻度压缩,在测试时不会损失信息损失。广泛的实验表明,我们的方法在图像语言和视频语言理解中都提高了MLLM的性能,同时也大大降低了培训成本并提高了推理效率。
通过视觉上下文压缩有效的大型多模式模型
主要关键词




相关文件推荐





























