
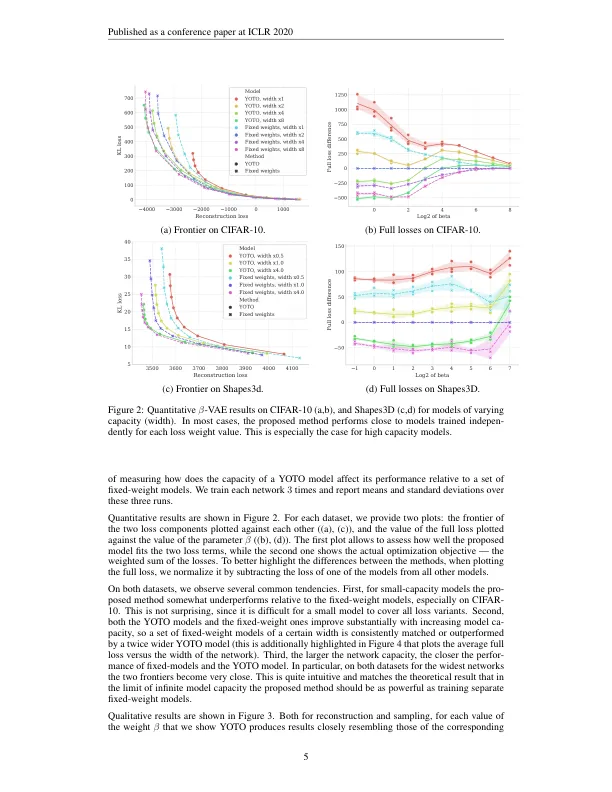
深网的损失条件培训
主要关键词




相关文件推荐




























主要关键词