
机构名称:
¥ 1.0
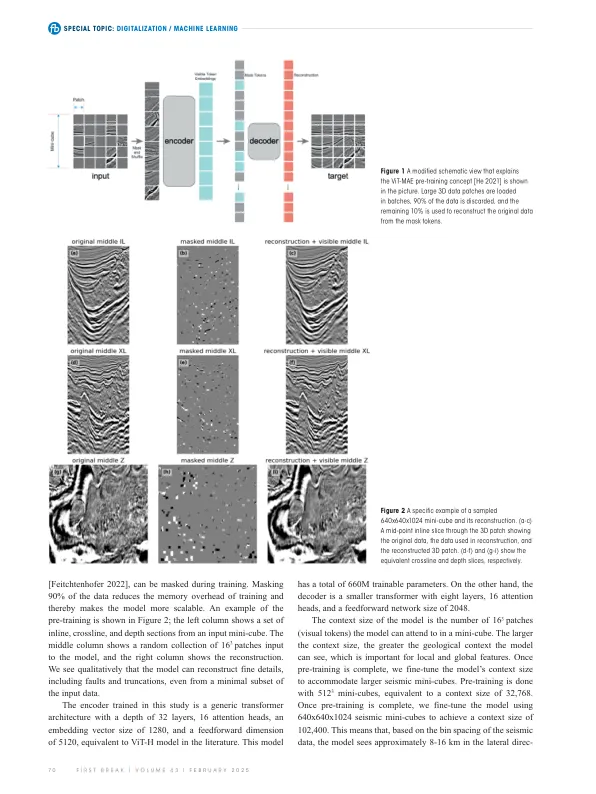
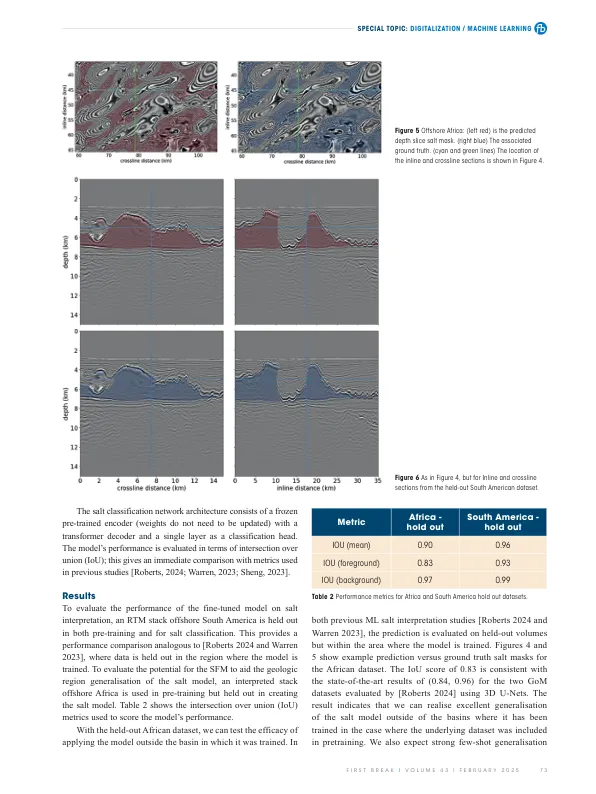
方法模型体系结构图1中示意性地显示的模型体系结构基于带有视觉变压器(VIT)骨干的胶带自动编码器(MAE),如He等人所述。[2021],修改为处理3D地震量。输入地震数据被分为重叠的迷你立方体,后者进行了增强,例如内联/跨线翻转。该模型最初适用于2D图像创建的VIT-MAE设计至3D,将16个3个贴片(视觉令牌)投射到1280长的矢量嵌入的集合中。在每个训练步骤中,从全局数据集中选择了一批迷你立方体,掩盖了90%的补丁,其余的10%用于重建原始的迷你立方体。学习目标是使用均方误差(MSE)度量的掩盖贴片的像素空间重建精度。
缩放地震基础模型
主要关键词



相关文件推荐





























