机构名称:
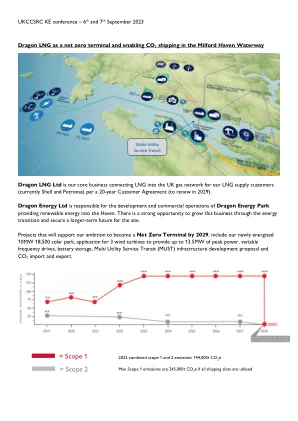
¥ 3.0
机器学习中的中心假设是观察结果是独立的,并且是分布的(i.i.d.)关于固定但未知的概率分布。在此假设下,已经提出了对高级算法设计中模型的可学习性或导致的阐述(Boser等,1992)。但是,在许多实际应用中,收集的数据可以取决于I.I.D。假设不存在。社区中有关数据的依赖性以及如何依赖的方式进行了广泛的讨论(Dehling和Philipp,2002; Amini and Usunier,2015年)。使用相互依存的数据学习。近年来建立依赖设定的概括理论已引起人们的兴趣(Mohri和Rostamizadeh,2008,2009; Ralaivola et al,2010; Kuznetsov and Mohri,2017)。在这个方向上的一项主要研究线模拟了各种类型的混合模型的数据依赖性,例如α-混合(Rosen- Blatt,1956年),β-混合(Volkonskii和Rozanov,1959年),φ -Mixing(ibragimov,1962)和η-混合(Kontorovich(Kontorovich),以及2007年,以及2007年,以及2007年,以及2007年)。混合模型已在统计学习理论中使用,以建立基于Rademacher复杂性(Mohri和Rostamizadeh,2009,2010; Kuznetsov and Mohri,2017)或算法稳定性(Mohri和Ros-Tamizadeh和Ros-Tamizadeh,2008,2008,2008; He Hean,2008; He Hean Indepental commution and kont and kont and kont and kont and kont and kont and kont and kont and kont and kont,技术(Yu,1994)。在这些模型中,混合系数在数据之间测量了数据之间的依赖性。另一项工作线(称为脱钩),通过分解一组依赖性随机变量来研究复杂系统的行为
在图中学习的概括范围
主要关键词





相关文件推荐