XiaoMi-AI文件搜索系统
World File Search System推理

多阶段推理:解锁认知自主权...
如前所述,依靠静态预训练数据完成任务的体系结构缺乏集成跨模式数据的能力(Ye等,2023)。当人形机器人处理听力,触摸或反应不一致时,这直接引起语义歧义(Pramanick&Rossi,2024)。尽管某些研究尝试了多模式融合技术,但进展仍然有限,不足以为人形机器人提供与人类相同的适应能力(Yuan等,2024)。为了解决这一差距,这项研究提出了一个多幕科推理体系结构作为创新解决方案。它旨在利用多幕科推理来优化类人类机器人在当前技术缺点基于视觉,听觉和触觉数据的跨模式中认知自主权的关键挑战。

现在安全! #1007-01-07-25 -AI培训与推理
在我们启动2025年第一个播客之前,我想花点时间向所有人保证,这个名为“ Security!”的播客都不会变成“现在的AI!”。我非常意识到,到2024年底,是的,今天,对于2025年的第一个播客,我们已经并且将花时间看着多年来在大学和商业实验室的倒地室中静静地沸腾的东西。这个播客有时会偏离遥远的地方,谈到了健康,科幻小说,Voyager航天器,甚至是自制的便携式声音枪。所有这些转移的基础是使它们走的基础科学和技术。以及在我关注AI的最新案例中,我从听众那里收到的所有反馈都表明,这是一个深切共享的感兴趣的话题。




通过角色的选择和价值 - 信念 - 态度推理使大型语言模型与人类的意见结盟
用大语言模型(LLM)推理和预测人类意见是必不可少的但具有挑战性的。当前的方法采用角色扮演的角色,但面对两个主要措施:LLMS甚至对一个无关的角色也很敏感,最多可以改变预期的30%; LLM无法战略性地推理人类。我们提出了开场链(COO 1),这是一种简单的四步解决方案建模,如何用personae推理,由价值 - 宽容 - 态度(VBN)the-Ory进行推理。COO将明确的人(人口统计学和意识形态)和卑鄙的人物(历史观点)区分了:(1)将无关的属性与显式人物过滤; (2)将隐式人物排名为选择top-k的优先列表; (3)提出新颖的VBN推理,以提取用户的环境和个人价值,信念和规范变量,以进行准确可靠的预测; (4)迭代VBN推理,并逐渐更大的隐式角色列表来处理潜在的角色不足。COO通过仅提示5个推论呼叫来有效地实现新的最新观点预测,从而将先前的技术提高了多达4%。值得注意的是,通过COO的数据进行微调LMS导致观点一致的模型明显高达23%。

heroz 选择 supermicro superblade 来增强 ai 推理......
简介 HEROZ 专注于作为各行业价值创造源泉的“核心业务”,并在核心业务中实现高价值的现实世界 AI 技术。HEROZ 的 AI 工程师开发了著名的 AI-Shogi,该游戏击败了专业的 Shogi 选手。他们继续每天致力于开发其他 AI 工具,包括机器学习,最终开发了 Shogi Wars、CHESS HEROZ 和 BackgammonAce 等游戏。HEROZ 已经连续三年参加世界计算机 Shogi 锦标赛。HEROZ 曾多次获得冠军和亚军。HEROZ 还作为日本深度学习协会 (JDLA) 的成员正在开发一种新的 AI 系统。HEROZ 也是日本人工智能学会的支持成员,他们紧跟 AI 的前沿趋势。除了智力游戏之外,HEROZ 开发的 AI 在包括主要金融机构在内的许多其他行业中发挥着关键作用。

ARGMED-AGENT:通过论证方案解散的解释临床决策推理
摘要 - 在临床推理中使用大型语言模型(LLM)有两个主要障碍。首先,尽管LLM在自然语言处理(NLP)任务中表现出巨大的希望,但它们在复杂的推理和计划中的表现却没有期望。其次,LLM使用不可解释的方法来做出与临床医生的认知过程根本不同的临床决策。这导致用户不信任。在本文中,我们提出了一个称为argdrestents的多代理框架,该框架旨在使基于LLM的代理通过互动来解释临床决策推理。Argmed-通过论证方案进行临床讨论(一种用于建模临床推理中认知过程的推理机制),然后将论证过程构造为对有冲突关系的指示图构建论证过程。最终,使用符号求解器来确定一系列理性和连贯的论点来支持决策。我们构建了一个正式的Argmed代理模型,并为理论保证提供了当前的猜想。Argmed-Agents使LLM可以通过以自定向方式产生推理的解释来模仿临床论证推理的过程。设置实验表明,与其他及时方法相比,Argsments不仅提高了复杂的临床决策推理问题的准确性,而且更重要的是,它为用户提供了提高其信心的决策解释。索引术语 - 临床决策支持,大语言模型,多代理系统,可解释的AI
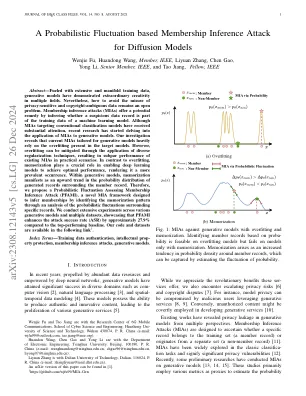
基于概率波动的会员推理攻击
摘要 - 富含广泛和流动的培训数据,生成模型在多个领域表现出了非凡的创造力。尽管如此,如何避免滥用对隐私敏感和版权的数据仍然是一个开放的问题。会员推理攻击(MIAS)通过推断可疑数据记录是机器学习模型的培训数据的一部分,从而提供了潜在的补救措施。尽管针对常规分类模型的MIA已引起了很大的关注,但最近的研究已开始研究MIA在生成模型中的应用。我们的研究表明,针对生成模型量身定制的当前MIA严重依赖于目标模型中存在的过度拟合。但是,可以通过应用各种正则化技术来缓解过度拟合,从而导致现有MIA在实际情况下的表现不佳。与过度拟合相比,记忆在使深度学习模型实现最佳性能中起着至关重要的作用,从而使其变得更加普遍。在生成模型中,记忆表现为围绕成员记录的记录的概率分布的上升趋势。因此,我们提出了一种评估成员推理攻击(PFAMI)的概率波动,这是一种新型的MIA框架,旨在通过分析围绕特定记录的概率波动来识别记忆模式来推断成员资格。我们的代码和数据集可在以下链接1中找到。我们对各种生成模型和多个数据集进行了广泛的实验,这表明PFAMI与表现最好的基线相比,PFAMI将攻击成功率(ASR)提高了约27.9%。

查看,比较,决定:通过多视图的多路推理减轻大型视觉模型中的幻觉
最近,大型视觉模型(LVLM)在多模式上下文理解中表现出了令人印象深刻的能力。但是,他们仍然遭受幻觉问题,即与图像内容产生不一致的输出。为了减轻幻觉,先前的研究主要集中于使用自定义数据集对LVLM进行重新培训。al-尽管有效,但它们本质上带有额外的计算成本。在本文中,我们提出了一个无培训的框架MVP,旨在通过通过Multimi-v iew Multi-p ath的理由来减少LVLMS的天生能力来减少幻觉。具体来说,我们首先设计了一种多视图信息寻求信息的策略,以彻底了解IMEAM中的全面信息,该信息丰富了原始愿景编码器在LVLMS中捕获的一般全球信息。此外,在答案解码期间,我们为每种信息视图提出了多路推理,以量化和集结多个解码路径中每个电位的确定性得分,并效法确定输出答案。通过完全掌握图像中的信息,并在解码时仔细考虑了潜在的范围的确定性,我们的MVP可以有效地减少LVLM中的幻觉。广泛的实验证明了我们提出的MVP可以显着减轻四个众所周知的LVLM的幻觉概率。更重要的是,MVP是插件,可以与其他解码方法集成,以进行更多的增强。源代码可在以下网址提供:https://github.com/gasolsun36/mvp。