XiaoMi-AI文件搜索系统
World File Search SystemMiSeq

phi29 样 Microbacterium foliorum podovirus 噬菌体的完整基因组序列 PineapplePizza
使用氯化锌沉淀法(7)从高滴度裂解物中提取 DNA,使用 NEBNext Ultra II 试剂盒(New England Biolabs,马萨诸塞州伊普斯威奇)制备用于测序,并使用匹兹堡噬菌体研究所(宾夕法尼亚州匹兹堡)的 Illumina MiSeq 仪器(v3 试剂)进行测序。对总共 1,056,847 个单端 150 bp 读数进行 9,214 倍覆盖度的测序。分别使用 Newbler v2.9 和 Consed v29.0 进行组装和质量控制检查(8, 9)。PineapplePizza 的基因组有 16,662 个碱基对,G + C 含量为 53.6%。没有测序读数超出基因组末端,基因组末端的 101 bp 反向重复与共价结合的末端蛋白一致,如 phi29(10)。使用 NCBI BLASTn (11) 进行全基因组比对,结果显示与其他 Microbacterium 噬菌体无显著的核苷酸序列相似性,PineapplePizza 被归类为单一基因。使用 Glimmer v3.02 (12) 和 GeneMark v2.5 (13) 自动注释 PineapplePizza 的基因组,然后使用 Phamerator (14)、DNA Master v5.23.6 ( http://phagesdb.org/DNAMaster/ )、PECAAN、BLAST (11) 和 HHPred (15) 手动细化。Aragorn v1.2.38 (16) 或 tRNAscan-SE v2.0 (17) 未鉴定出 tRNA 基因。所有分析均使用默认设置进行。

微生物社区的多样性和潜在功能,以应对三大峡谷水库,中国
河流和水库细菌群落是河流生物群落和生态系统结构的最基本部分,在河流生物过程中起着重要作用。然而,尚不清楚高度调节的大坝水库如何影响土壤和沉积物细菌群落。在三个峡谷储层(TGR)的过渡部分中,使用Illumina Miseq测序研究了细菌群落的时间分布模式。总共有106,682个特征属于细菌王国,包括95个门,228个类别,514个订单,871个家庭,1959年属和3,053种。具有水位调节,香农多样性指数和观察到的物种差异很大,辛普森偶数没有显着差异。在高水位时期(10月)和低水位时期(6月),proteeobacteria,Acidobacteri和Chloroflexi都是最丰富的门。虽然基于PCA图和Circos图,微生物群落结构已发生了很大变化。lefse方法用于识别分类的细菌类群,低水位和高水位时期之间存在明显的丰度差异。KOS(KEGG矫正)途径富集分析,以研究组中的功能和相关代谢途径。在某种程度上可以推断,水位法规通过影响微生物群落的代谢影响社区的成长。
2025 年降价
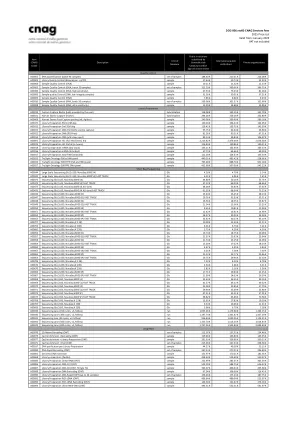
质量控制 A00002 DNA 定量(批次 96 个样本)样本组 188.40 欧元 211.01 欧元 226.08 欧元 A00003 库质量控制(生物分析仪 + qPCR)样本 27.44 欧元 30.73 欧元 32.93 欧元 A00004 样本质量控制(DNA)样本 10.11 欧元 11.32 欧元 12.13 欧元 A00005 样本质量控制(DNA,批次 50 个样本)样本组 322.29 欧元 360.96 欧元 386.75 欧元 A00490 样本质量控制(DNA,高灵敏度)样本 67.53 欧元 75.63 欧元 81.04 欧元 A00006 样本质量控制(DNA,低完整性样本)样本 31.26 欧元 35.01 欧元 37.51 欧元A00009 样品质量控制 (RNA) 样品 7.86 € 8.80 € 9.43 € A00010 样品质量控制 (RNA, 批次 50 个样品) 样品组 269.08 € 301.37 € 322.90 € A00008 样品质量控制 (RNA, 超灵敏度) 样品 13.29 € 14.88 € 15.95 € 文库制备 A00019 定制捕获 Roche (用户提供诱饵) 杂交 118.08 € 132.25 € 141.70 € A00021 人类外显子组捕获 (Roche) 杂交 294.00 € 329.28 € 352.80 € A00468 人类外显子组捕获后池化 (v8, Agilent) 样品 240.98 € 269.90 € 289.18 欧元 A00472 文库制备 5hmC-EM-Seq 样本 120.04 欧元 134.44 欧元 144.05 欧元 A00015 文库制备 5mC-EM-Seq 样本 119.42 欧元 133.75 欧元 143.30 欧元 A00023 文库制备 DNA(用于 Roche 外显子组捕获)样本 55.75 欧元 62.44 欧元 66.90 欧元 A00012 文库制备 DNA(无 PCR)样本 81.26 欧元 91.01 欧元 97.51 欧元 A00014 文库制备 DNA(超低输入)样本 89.14 欧元 99.84 欧元 106.97 欧元 A00091 文库制备 HiC(完整 HiC/OmniC 试剂盒)样本 2,213.82 欧元2,479.48 欧元 2,656.58 欧元 A00013 文库制备 HiC 部分(内部)样本 116.84 欧元 130.86 欧元 140.21 欧元 A00018 文库制备 mRNA(低输入)样本 136.11 欧元 152.44 欧元 163.33 欧元 A00016 文库制备 mRNA(链)样本 57.73 欧元 64.66 欧元 69.28 欧元 A00017 文库制备总 RNA(链)样本 111.28 欧元 124.63 欧元 133.54 欧元 A00025 TruSight Oncology 500 ctDNA 面板样本 440.55 欧元 493.42 欧元 528.66 欧元 A00026 TruSight Oncology 500 FFPE DNA 和 RNA 面板样本793.48 欧元 888.70 欧元 952.18 欧元 A00027 TruSight Oncology 500FFPE DNA 面板样本 452.68 欧元 507.00 欧元 543.22 欧元 短读测序 A00044 大规模测序 Gb (2x150, NovaSeq 6000 S4) Gb 4.28 欧元 4.79 欧元 5.14 欧元 A00045 大规模测序 Gb (2x150, NovaSeq 6000 S4) FAST TRACK Gb 6.21 欧元 6.96 欧元 7.45 欧元 A00473 测序 Gb (1x35, NovaSeq 6000 S4) Gb 44.80 欧元 50.18 欧元 53.76 欧元 A00474 测序 Gb (1x35,NovaSeq 6000 S4)快速通道 Gb 57.22 欧元 64.09 欧元 68.66 欧元 A00475 测序 Gb (1x35,NovaSeq 6000 S4,4D 通道) Gb 48.04 欧元 53.80 欧元 57.65 欧元 A00476 测序 Gb (1x35,NovaSeq 6000 S4,4D 通道)快速通道 Gb 61.02 欧元 68.34 欧元 73.22 欧元 A00046 测序 Gb (2x100,NovaSeq 6000 S1) Gb 23.44 欧元 26.25 欧元 28.13 欧元 A00047 测序 Gb (2x100,NovaSeq 6000 S1) 快速通道 Gb 29.76 欧元 33.33 欧元 35.71 欧元 A00048 测序 Gb (2x100, NovaSeq 6000 S2) Gb 16.56 欧元 18.55 欧元 19.87 欧元 A00049 测序 Gb (2x100, NovaSeq 6000 S2) 快速通道 Gb 21.04 欧元 23.56 欧元 25.25 欧元 A00050 测序 Gb (2x100, NovaSeq 6000 S4) Gb 9.65 欧元 10.81 欧元 11.58 欧元 A00051 测序 Gb (2x100, NovaSeq 6000 S4) 快速通道 Gb 12.42 欧元 13.91 欧元 14.90 欧元 A00054 测序 Gb (2x100, NovaSeq 6000 SP) Gb 28.57 欧元 32.00 欧元 34.28 欧元 A00055 测序 Gb (2x100, NovaSeq 6000 SP) 快速通道 Gb 35.92 欧元 40.23 欧元 43.10 欧元 A00707 测序 Gb (2x100, NovaSeq X 1.5B) Gb 10.09 欧元 11.30 欧元 12.11 欧元 A00704 测序 Gb (2x100, NovaSeq X 10B) Gb 6.01 欧元 6.73 欧元 7.21 欧元 A00682 测序 Gb (2x100, NovaSeq X 25B) Gb 3.75 欧元 4.20 欧元 4.50 欧元 A00056 测序 Gb (2x150, NovaSeq 6000 S1) Gb 16.74 欧元 18.75 欧元 20.09 欧元 A00057 测序 Gb (2x150, NovaSeq 6000 S1) FAST TRACK Gb 21.37 欧元 23.93 欧元 25.64 欧元 A00058 测序 Gb (2x150, NovaSeq 6000 S2) Gb 11.74 欧元 13.15 欧元 14.09 欧元 A00059 测序Gb (2x150, NovaSeq 6000 S2) 快速通道 Gb 15.20 欧元 17.02 欧元 18.24 欧元 A00060 测序 Gb (2x150, NovaSeq 6000 S4) Gb 4.87 欧元 5.45 欧元 5.84 欧元 A00065 测序 Gb (2x150, NovaSeq 6000 S4) 快速通道 Gb 6.25 欧元 7.00 欧元 7.50 欧元 A00063 测序 Gb (2x150, NovaSeq 6000 SP) Gb 21.22 欧元 23.77 欧元 25.46 欧元 A00064 测序 Gb (2x150, NovaSeq 6000 SP) 快速通道 Gb 26.75 欧元29.96 欧元 32.10 欧元 A00706 测序 Gb (2x150, NovaSeq X 1.5B) Gb 7.32 欧元 8.20 欧元 8.78 欧元 A00676 测序 Gb (2x150, NovaSeq X 10B) Gb 4.34 欧元 4.86 欧元 5.21 欧元 A00670 测序 Gb (2x150, NovaSeq X 25B) Gb 2.82 欧元 3.16 欧元 3.38 欧元 A00066 测序 Gb (2x250, NovaSeq 6000 SP) Gb 17.71 欧元 19.84 欧元 21.25 欧元 A00067 测序 Gb (2x250, NovaSeq 6000 SP) 快速通道 Gb 21.99 欧元 24.63 欧元 26.39 欧元 A00068 测序 Gb (2x50, NovaSeq 6000 S1) Gb 32.63 欧元 36.55 欧元 39.16 欧元 A00069 测序 Gb (2x50, NovaSeq 6000 S1) 快速通道 Gb 41.27 欧元 46.22 欧元 49.52 欧元 A00070 测序 Gb (2x50, NovaSeq 6000 S2) Gb 23.08 欧元 25.85 欧元 27.70 欧元 A00071 测序 Gb (2x50, NovaSeq 6000 S2) 快速通道 Gb 29.90 欧元 33.49 欧元 35.88 欧元 A00074 测序Gb (2x50, NovaSeq 6000 SP) Gb 47.51 欧元 53.21 欧元 57.01 欧元 A00075 测序 Gb (2x50, NovaSeq 6000 SP) 快速通道 Gb 58.82 欧元 65.88 欧元 70.58 欧元 A00708 测序 Gb (2x50, NovaSeq X 1.5B) Gb 15.92 欧元 17.83 欧元 19.10 欧元 A00705 测序 Gb (2x50, NovaSeq X 10B) Gb 9.34 欧元 10.46 欧元 11.21 欧元 A00683 测序 Gb (2x50, NovaSeq X 25B) Gb 5.98 欧元 6.70 欧元 7.18 欧元A00039 测序通道 (150 次循环,v3,MiSeq) 运行 1,053.46 欧元 1,179.88 欧元 1,264.15 欧元 A00040 测序通道 (300 次循环,v2,MiSeq) 运行 1,197.74 欧元 1,341.47 欧元 1,437.29 欧元 A00041 测序通道 (50 次循环,v2,MiSeq) 运行 936.84 欧元 1,049.26 欧元 1,124.21 欧元 A00042 测序通道 (500 次循环,v2,MiSeq) 运行 1,353.70 欧元 1,516.14 欧元 1,624.44 欧元 A00043 测序通道 (600 次循环,v3,MiSeq) 运行1,737.36 欧元 1,945.84 欧元 2,084.83 欧元 长读 A00076 1D 天然条形码 (ONT) 样品组 212.07 欧元 237.52 欧元 254.48 欧元 A00079 Cas9 富集 + 条形码 (ONT) 样品 119.46 欧元 133.80 欧元 143.35 欧元 A00077 Cas9 富集 + 文库制备 (ONT) 样品 291.93 欧元 326.96 欧元 350.32 欧元 A00471 Cas9 富集 + 池 (ONT) 样品组 215.48 欧元 241.34 欧元 258.58 欧元 A00187 DNA 纯化文库制备前样品 44.27 欧元 49.58 欧元 53.12 欧元 A00080 DNA 快速条形码(ONT)样本组 247.33 欧元 277.01 欧元 296 欧元。80 欧元 A00081 基因组 DNA 提取样品 151.97 欧元 170.21 欧元 182.36 欧元 A00668 文库制备 (PacBio) 样品 458.64 欧元 513.68 欧元 550.37 欧元 A00085 文库制备直接 RNA (ONT) 样品 252.99 欧元 283.35 欧元 303.59 欧元 A00086 文库制备 DNA 1D (ONT) 样品 522.10 欧元 584.75 欧元 626.52 欧元 A00087 文库制备 DNA 1D (ONT, Flongle FC) 样品 363.07 欧元 406.64 欧元 435.68 欧元 A00089 文库制备 DNA 条形码 (ONT) 样品 97.04 欧元 108.68 欧元 116.45 欧元A00090 文库制备 DNA 快速 (ONT)(最多 24 个样本)样本组 156.46 欧元 175.24 欧元 187.75 欧元 A00092 文库制备 PCR-cDNA (ONT) 样本 436.64 欧元 489.04 欧元 523.97 欧元 A00093 文库制备 PCR-cDNA 条形码 (ONT) 样本 144.30 欧元 161.62 欧元 173.16 欧元 A00094 文库制备 Ultra HMW DNA (ONT) 样本 493.31 欧元 552.51 欧元 591.97 欧元

相对 qPCR 定量分析丛枝菌根真菌对植物根系的定植
摘要 丛枝菌根真菌 (AMF) 是一种有益的土壤真菌,可以促进宿主植物的生长。准确量化植物根部中的 AMF 非常重要,因为定植水平通常可以表明这些真菌的活性。根定植传统上用显微镜方法测量,该方法可以看到根内的真菌结构。显微镜方法劳动密集型,结果取决于观察者。在本研究中,我们提出了一种相对 qPCR 方法来量化 AMF,其中我们根据植物基因标准化了 AMF qPCR 信号。首先,我们在计算机上验证了引物对 AMG1F 和 AM1,并表明这些引物涵盖了植物根部存在的大多数 AMF 物种,而不会扩增宿主 DNA。接下来,我们基于对矮牵牛植物的温室实验将相对 qPCR 方法与传统显微镜检查进行了比较,这些植物的 AMF 根定植水平从非常高到非常低不等。最后,通过使用 MiSeq 对 qPCR 扩增子进行测序,我们通过实验证实引物对排除了植物 DNA,而主要扩增了 AMF。最重要的是,我们的相对 qPCR 方法能够区分 AMF 根定植的定量差异,并且与传统显微镜定量结果高度相关(Spearman Rho = 0.875)。最后,我们对显微镜和 qPCR 方法的优缺点进行了平衡的讨论。总之,测试的相对 qPCR 方法提供了一种可靠的替代方法来量化 AMF 根定植,与传统显微镜相比,该方法对操作员的依赖性更低,并且可扩展到高通量分析。

整个基因组宏基因组学作为益生菌分析的工具
许多可用于消费者的饮食产品,例如饮食补充剂,含有据称赋予人类健康益处的活微生物。有关于商业益生菌标签差异的报道,其中物种经常被错误分类或不存在,以及标签上未列出的微生物污染。这项研究的目的是更好地了解益生菌产品的质量,其标签的准确性以及使用整个基因组测序(WGS)宏基因组学鉴定潜在污染物和低水平成分的能力。在这项研究中,DNA从123种益生菌产物中纯化,并使用Illumina Miseq平台进行了元基因组测序。生成的序列用于鉴定具有基于新型内部K-MER数据库的独特物种特异性特异性特异性特异性特异性特异性标志的微生物成分。并行,使用培养依赖性方法,将产物的微生物含量生长用于单个集菌分离,然后使用WGS创建有益微生物的基因组序列数据库。此外,使用抗性基因识别剂和毒力发现者生物信息学工具来识别抗生素耐药性和毒力因子基因的存在。宏基因组方法中的一个挑战是在存在大量有意添加的物种(如乳杆菌和双叶杆菌)的情况下,以较少的数量(成分,污染物和病原体)来检测微生物。这些研究将使消费者可用的实时微生物补充剂的内容有更好的了解,并提供一种分析途径来检测低量的有害病原体。避免了这两种方法:使用特定的噬菌体和/或纯化的噬菌体赖氨酸来减少产品的本地微生物,以改善对低水平微生物成分的检测并使用靶标的物质测序。

各种微生物组的综合宏基因组分析
犬类肠道微生物组是兽医和人类健康研究的关键模型,但由于方法上的变化而出现了不一致的发现。本研究提出了一个三部分的数据集,以阐明DNA提取,底漆选择和测序平台如何影响微生物分析。首先,我们使用五个DNA隔离试剂盒,多个库协议和四个测序平台(Illumina Miseq/Novaseq,Ont Minion,Pacbio Sequel IIE),启用16S RRNA和Shotgun测序技术的直接比较。第二,我们使用Zymo高分子量(ZHMW)和Zymo Magbead(ZMB)提取试剂盒分析了八只共同犬的40个粪便样品,以评估纵向提取效果。第三,我们使用合成模拟群落和人/犬粪便样品评估了三个16S引物系统(标准ONT,PACBIO,并用退化碱基修饰)来量化底漆偏见。通过整合合成和生物学重复,该数据集提供了标准化资源,用于基准生物信息学管道并改善跨研究可比性。该研究生成了75.3FGB的新测序数据:ZHMW- ZMB比较的43.45FGB,22.61FGB用于引物评估,而单样本分析中的9.19FGB。与先验数据的31.5FGB结合在一起,总数据集超过106FGB,包括所有分析输出。这些资源提高了不同实验室工作流程的犬类肠道微生物组研究的方法论透明度和准确性。

HIV-1 DNA测试在病毒血症患者中比HIV-1 RNA测试识别更多的耐药性
抗抗性相关的主要和次要突变与核OS(T)IDE和非核苷逆转录酶抑制剂(NRTIS和NNRTIS),蛋白酶抑制剂(PIS)和综合酶抑制剂(INIS)通过Sanger(现象GLES GRESSENSE gt insensense,Ontosense,Onagrive Biogence)鉴定如前所述[51]如前所述。从全血EDTA SAM PLE中提取基因组DNA后,进行HIV-1 POL区域的一式三份嵌套聚合酶链反应放大。放大器,然后在Illumina Miseq平台上进行2×150个基本配对末端测序。配对末端读数被连接在一起,并以密码子感知方式将读数与NL43 GenBank:KM390026.1参考序列对齐。质量指标已适当,以在所有位置进行终止对齐覆盖> 1000倍,并且在所有位置上> 30 phred评分。一种幼稚的贝叶斯分类模型用于单独评估apobecec诱导的g的证据。超级读数,并评估其余的读数的变异频率。报告阈值设定为10%,以最大程度地减少ApoBec诱导的超伪阳性的影响。对于在不太可能发生APOBEC诱导的变化的位置发生的耐药性突变,最小报告阈值为3%。基于基因型的抗病毒(ARV)易感性评估是使用专有的ALGO RITHM进行的,该ALGO RITHM合并了每种药物的临床试验数据,> 120 000次匹配的基因型 - 表型结果。病毒载荷测量发生在电阻测试前不超过5天或3天,并使用Cobas Ampliprep/Cobas Taqman HIV-1分析进行。

细菌群落结构中的精细尺度一致性,来自iLlumina上的短读和纳米孔上的长阅读的海洋沉积物
在开发高通量测序仪后,环境原核生物群落通常是通过在16S域上用遗传标记来描述的。然而,由于底漆的选择和读取长度,简短读取测序遇到了系统发育覆盖率和分类分辨率的局限性。在这些关键点上,纳米孔测序(一种适用于长读的元编码的上升技术)被低估了,因为其每读的错误率相对较高。在这里,我们比较了模拟社区中的原核生物群落结构和两个对比的红树林遗址的52个沉积物样本,由16SV4-V5标记上的短读描述(Ca。0.4kpb)通过Illumina测序分析(Miseq,v3),由长读细菌对细菌的描述几乎完整16s(Ca。1.5 kpb)由牛津纳米孔(Minion,R9.2)分析。短读和长阅读从模拟中检索了所有细菌属,尽管两者都显示出与所期待的比例相似的偏差。从沉积物样品中,具有覆盖范围的读数稀有性,在单例过滤后,共同恩赐和Procrustean测试表明,从短读和长长读取的细菌社区结构显着相似,表明位点之间的相当对比度和站点内相干的海岸方向是可比的。在我们的数据集中,分别将84.7和98.8%的短阅读分别分别分配给了相同的物种和属,而不是长阅读所检测到的物种和属。长期16的底漆特异性使其能够检测到309个家庭中的92.2%,而在短16SV4-V5检测到的448属中,有87.7%。长阅读记录了973个未检测到的额外分类单元,其中91.7%被确定为该属等级,其中一些属于11个独家门,尽管仅占长期读数的0.2%。

ExpressPlex™ 2.0 文库制备试剂盒 – 384 孔
正在申请专利的 ExpressPlex 2.0 文库制备试剂盒采用方便的 384 孔 PCR 板配置,可用于高通量多重文库制备。此升级版 ExpressPlex 使用 seqWell 的高性能 TnX ™ 转座酶,该转座酶专为 NGS 文库制备而设计。扩增子 (>350 bp) 和质粒 DNA 是适合该试剂盒的标准输入。附录 E 重点介绍了可以针对小型微生物全基因组测序进行的修改。ExpressPlex 文库与 Illumina MiSeq ™ 、NextSeq ™ 、iSeq ™ 和 NovaSeq ™ 测序平台兼容。每个 ExpressPlex 2.0 - 384 孔试剂盒都包含足够的试剂,可从 384 或 1,536 个单独的 DNA 样本制备与 Illumina 兼容的文库。每个库的标准制备量为 384 个样本,每个试剂盒最多 1,536 个样本。有四种不同的试剂盒可用于从 1,536 个样本中制备文库,在一次测序运行中可加载总共 6,144 种条形码组合。这种多重文库制备程序针对每 8 µl 反应 0.5 - 20 ng 质粒或扩增子 DNA 的输入进行了优化,通常可生成 400 – 1,200 bp 的文库片段长度。文库片段长度取决于 DNA 的质量和所用的磁珠清理率。使用 ExpressPlex 文库制备试剂盒的主要优势和好处是简化的一步式多重文库制备工作流程,可在 40 倍的 DNA 输入浓度范围内自动标准化每个样本的读取输出,同时最大限度地减少人工和耗材成本。使用 ExpressPlex 2.0 – 384 孔试剂盒,可在 120 分钟内制备 384 重文库以进行文库 QC 和测序,手动操作时间不到 30 分钟。

重新布线蛋白质序列和结构生成模型以增强蛋白质稳定性预测
快速增长的数据需要可靠且持久的存储解决方案。DNA由于其高信息密度和长期稳定性而成为一种有希望的媒介。但是,DNA存储是一个复杂的过程,每个阶段都会引入噪声和错误,包括合成错误,存储衰减和测序错误,它需要对错误校正的代码(ECC)才能获得可靠的数据恢复。要设计一种最佳数据恢复方法,对DNA数据存储通道中噪声结构的综合理解至关重要。由于在体外运行DNA数据存储实验仍然很昂贵且耗时,因此必须进行模拟模型,以模仿真实数据中的误差模式并模拟实验。现有的仿真工具通常依赖固定的误差概率或特定于某些技术。在这项研究中,我们提出了一个基于变压器的生成框架,用于模拟DNA数据存储通道中的错误。我们的模拟器将寡素(DNA序列写入)作为输入,并生成错误的输出DNA读取,与常见DNA数据存储管道的真实输出非常相似。它捕获了随机和有偏见的误差模式,例如K-MER和过渡错误,无论过程或技术如何。我们通过分析两个使用不同技术处理的数据集来证明模拟器的有效性。在第一种情况下,使用Illumina Miseq处理,由DDS-E-SIM模拟的序列显示出与原始数据集的总误率偏差仅为0.1%。第二次使用牛津纳米孔技术进行的偏差为0.7%。基本级别和K-MER错误与原始数据集紧密对齐。此外,我们的模拟器从35,329个序列中生成100,743个独特的橄榄岩,每个序列读取五次,证明了其同时模拟偏置错误和随机属性的能力。我们的模拟器以优越的精度和处理多种测序技术的能力优于现有的模拟器。