XiaoMi-AI文件搜索系统
World File Search SystemProcessor

纠结:集成量子的传统处理器......
量子计算机利用量子物理现象创建专用硬件,可以高效执行针对纠缠叠加数据的算法。该硬件必须连接到传统主机并由其控制。然而,可以说,迄今为止的主要好处在于重新表述问题以利用纠缠叠加,而不是使用奇异的物理机制来执行计算——这种重新表述往往会为传统计算机产生更高效的算法。并行位模式计算并不模拟量子计算,但提供了一种使用非量子、位级、大规模并行、SIMD 硬件来高效执行利用叠加和纠缠的广泛算法的方法。正如量子硬件需要传统主机一样,并行位模式硬件也需要。因此,当前的工作提出了 Tangled:一种简单的概念验证传统处理器设计,其中包含一个与集成并行位模式协处理器 (Qat) 紧密耦合的接口。通过构建指令集、为流水线实现构建完整的 Verilog 设计,以及观察接口在执行涉及纠缠、叠加值运算的简单量子启发算法中的有效性,研究了这种在传统计算和量子启发计算之间接口的可行性。
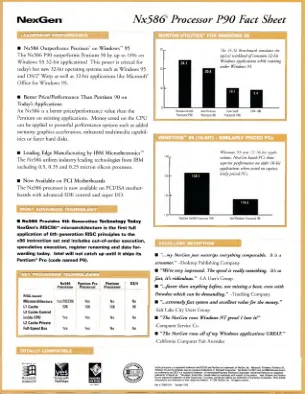
NX586“处理器P90概况表
■NX586提供了第六代技术学今天Nexgen的RISC86™Microharchitecture是第六代RISC原则在X86指令集中的首次完整应用,并包括排序执行,投机性执行,注册重命名,重命名和数据伪造。Intel必须等待奔腾*'Pro来利用这种高水平的技术。

量子处理器上的时间晶体本征态序
Xiao Mi 1.11 , Matteo Ippoliti 2.11 , Chris Quintana 1 , Ami Greene 1 , Zijun Chen 1 , Jonathan Gross 1 , Frank Arute 1 , Kunal Arya 1 , Juan Atalaya 1 , Ryan Babbush 1 , Joseph C. Bardin 1.3 , Joao Basso 1 , Andreas Bengtsson 1 , Alexander Bilmes 1 , Alexandre Bourassa 1.4 , Leon Brill 1 , Michael Broughton 1 , Bob B. Buckley 1 , David A. Buell 1 , Brian Burkett 1 , Nicholas Bushnell 1 , Benjamin Chiaro 1 , Roberto Collins 1 , William Courtney 1 , Dripto Debroy 1 , Sean Demura 1 , Alan R. Derk 1 , Andrew Dunsworth 1 , Daniel Eppens 1 , Catherine Erickson 1 , Edward Farhi 1 , Austin G. Fowler 1 , Brooks Foxen 1 , Craig Gidney 1 , Marissa Giustina 1 , Matthew P. Harrigan 1 , Sean D. Harrington 1 , Jeremy Hilton 1 , Alan Ho 1 , Sabrina Hong 1 , Trent Huang 1 , Ashley Huff 1 , William J. Huggins 1 , L. B. Ioffe 1 , Sergei V. Isakov 1 , Justin Iveland 1 , Evan Jeffrey 1 , Zhang Jiang 1 , Cody Jones 1 , Dvir Kafri 1 , Tanuj Khattar 1 , Seon Kim 1 , Alexei Kitaev 1 , Paul V. Klimov 1 , Alexander N. Korotkov 1,5 , Fedor Kostritsa 1 , David Landhuis 1 , Pavel Laptev 1 , Joonho Lee 1.6 , Kenny Lee 1 , Aditya Locharla 1 , Erik Lucero 1 , Orion Martin 1 , Jarrod R. McClean 1 , Trevor McCourt 1 , Matt McEwen 1.7 , Kevin C. Miao 1 , Masoud Mohseni 1 , Shirin Montazeri 1 , Wojciech Mruczkiewicz 1 , Ofer Naaman 1 , Matthew Neeley 1 , Charles Neill 1 , Michael Newman 1 , Murphy Yuezhen Niu 1 , Thomas E. O'Brien 1 , Alex Opremcak 1 , Eric Ostby 1 , Balint Pato 1 , Andre Petukhov 1 , Nicholas C. Rubin 1 , Daniel Sank 1 , Kevin J. Satzinger 1 , Vladimir Shvarts 1 , Yuan Su 1 , Doug Strain 1 , Marco Szalay 1 , Matthew D. Trevithick 1 , Benjamin Villalonga 1 , Theodore White 1 , Z. Jamie Yao 1 , Ping Yeh 1 , Juhwan Yoo 1 , Adam Zalcman 1 , Hartmut Neven 1 , Sergio Boixo 1 , Vadim Smelyanskiy 1 , Anthony Megrant 1 , Julian Kelly 1 , Yu Chen 1 , S. L. Sondhi 8,9 , Roderich Moessner 10 ,


超声处理器零件号VCX130
请全部阅读手册。提供必要的指导和指导,以帮助确保该设备的成功操作。观察以下内容:电源,转换器和高频电缆中存在高压。这些设备中的任何一个都没有可提供用户的零件。不要尝试删除电源盖或转换器盒。在打开电源时,请勿触摸设备上的任何打开的电缆连接。请勿使用与高压电缆断开连接的转换器的电源。电缆中存在高压,可能会构成冲击危险。在设备运行时,请勿尝试断开转换器高电压电缆。必须用3台插头正确接地电源。测试电源插座,以在插入单元之前进行适当的接地。将超声电源安装在没有过多灰尘,污垢,爆炸性或腐蚀性烟雾的区域中,并保护温度和湿度的极端。(有关规格,请参见第5页)不要将电源放置在通风罩中。
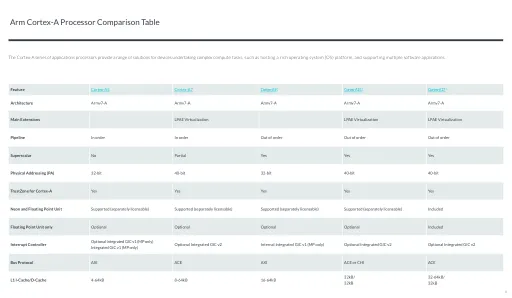
ARM Cortex-A处理器比较表
中断控制器外部GICV3外部GICV3外部GICV3外部GICV3外部GICV4外部GICV3外部GICV3外部GICV4外部GICV4外部GICV4外部GICV3外部GICV3外部GICV3外部GICV3外部GICV4外部GICV4外部GICV4外部GICV4外部GICV4外部GICV4外部GICV4外部GICV4

Lagarto 在 BSC 制造第一台 RISC-V 处理器
DRAC 项目(文件编号为 001-P-001723)由欧盟区域发展基金在 2014-2020 年加泰罗尼亚 ERDF 运营计划框架内共同资助 50%,资助金额为 2,000,000.00 欧元,并得到加泰罗尼亚政府的支持。版权所有 2020 © 保留所有权利。

使用并行视觉处理器实现无人机的跟踪控制
摘要 — 本文介绍了一种基于视觉的控制策略,使用一种新型视觉传感器跟踪地面目标,该传感器为每个像素元素配备一个处理器。这使得计算机视觉任务能够以高效的方式直接在焦平面上执行,而无需使用单独的通用计算机。该策略使小型、灵活的四旋翼无人机 (UAV) 能够以最少的计算工作量和低功耗从近距离跟踪目标。为了评估该系统,我们瞄准了一辆由混沌双摆轨迹驱动的车辆。目标接近度和车辆的巨大、不可预测的加速度给无人机带来了挑战,使其难以保持在向下摄像头的视野 (FoV) 内。状态观察器用于平滑对目标位置的预测,并且重要的是估计速度。实验结果还表明,在目标能见度短时间内丢失期间,可以继续重新获取和跟踪目标。跟踪算法利用视觉传感器的并行特性,在与无人机控制器出现任何通信瓶颈之前实现高速图像处理。由于视觉芯片执行最密集的视觉信息处理,因此计算机上跟踪的所有控制在计算上是微不足道的。这项工作旨在开发出节能且只在信息周围传送有用数据的视觉敏捷机器人

英特尔酷睿双核处理器中的温度测量
现代 CPU 的核心频率和功率不断增加,正迅速达到这样一个临界点:CPU 频率和性能受到冷却技术所能提取的热量的限制。在移动环境中,随着外形尺寸变得越来越薄、越来越轻,这个问题变得越来越明显。移动平台通常会牺牲 CPU 性能来降低功耗和管理热量。通过降低皮肤温度和减少风扇噪音,这可以实现高性能计算,同时改善人体工程学。大多数可用的高性能 CPU 在芯片上提供热传感器,以进行热管理,通常采用模拟热二极管的形式。操作系统算法和平台嵌入式控制器读取温度并控制处理器功率。改进的热传感器直接转化为更好的系统性能、可靠性和人体工程学。在本文中,我们将介绍新的 Intel ® Core TM Duo 处理器温度传感功能,并介绍性能优势测量和结果。

超越 RV32I ISA 的 RISC-V 处理器验证
摘要 — RISC-V 处理器的开源架构为设计人员提供了灵活性,使他们能够为各种应用实现架构。然而,同样的优势也使验证过程变得困难,因为必须验证所有变体。拟议的项目将为扩展的 RISC V 架构创建一个验证环境。RISC-V 支持整数乘法和除法的“M”标准扩展以及控制和状态寄存器指令的“Zicsr”标准扩展。上述 ISA 类将使用基于 RV32I ISA 的 DUT 进行测试,并在 DUT 周围使用 UVM 环境来验证 M 和 Zicsr 功能。M 和 Zicsr 类型 ISA 经过验证,功能覆盖率为 95%。创建的 UVM 框架可以重复用于验证其他指令集架构。