XiaoMi-AI文件搜索系统
World File Search System变形金刚

使用NLP的文本到图像和图像到文本翻译。 -ijrpr
文本对图像和图像到文本翻译是在自然语言处理(NLP)和计算机视觉的交集中迅速发展的域。文本对图像生成涉及基于描述性文本输入的图像的综合。此过程利用高级机器学习模型,例如生成对抗网络(GAN)和扩散模型,创建与提供文本相匹配的连贯性和上下文相关的视觉效果。这些模型学习了文本描述和视觉特征之间的复杂关系,从而可以生产从现实的照片到艺术渲染的各种图像。相反,图像到文本翻译的重点是从视觉输入中生成文本描述。此任务利用卷积神经网络(CNN)与复发性神经网络(RNN)或变形金刚结合进行分析和解释图像的技术。目标是提取相关信息,捕获诸如对象,动作和上下文之类的细节,并将其转换为自然语言描述。这两个过程都在各个领域都有重要的应用程序,包括创建内容,视障人士的可访问性以及增强技术中的用户互动。

视觉的元构基准
近年来,变形金刚[9]在各种计算机视觉任务[10],[11],[12],[13]中表现出了不前期的成功。变压器的能力长期以来一直归因于其注意力模块。因此,已经提出了许多基于注意力的令牌混合器[4],[5],[14],[15],[16],目的是为了增强视觉传输(VIT)[11]。尽管如此,一些工作[17],[18],[19],[20],[21]发现,通过用空间MLP [17],[22],[23]或傅立叶变换[18]等简单操作员更换变压器中的注意模块,结果模型仍然会产生令人鼓舞的性能。沿着这条线,[24]将变压器摘要为一种称为元构造器的通用体系结构,并假设是元构造者在实现竞争性能中起着至关重要的作用。To verify this hypothesis, [24] adopts embarrassingly simple operator, pooling, to be the token mixer, and discovers that PoolFormer effectively outperforms the delicate ResNet/ViT/MLP-like baselines [1], [2], [4], [11], [17], [22], [25], [26], which con- firms the significance of MetaFormer.

参数自适应非模型的状态估计结合了注意机制和LSTM
如今,状态估计被广泛用于诸如自动驾驶和无人机导航之类的领域。但是,在实际应用中,很难获得准确的目标运动模型和噪声协方差。这导致传统卡尔曼过滤器的估计准确性降低。为了解决此问题,本文提出了一种基于注意参数学习模块的自适应模型免费状态估计方法。此方法将变形金刚的编码器与长期短期内存网络(LSTM)结合在一起,并通过offline学习测量数据获得了系统的操作特性,而无需对系统动力学和测量特性进行建模。此外,根据注意力学习模块的输出,期望最大化(EM)算法用于估计在线系统模型参数,并使用KalmanFureter来获得状态估计。使用GPS轨迹路径数据集验证了本文,实验结果表明,所提出的参数自适应模型自由状态估计方法的估计精度比其他模型具有更好的估计精度,从而提供了一种使用深度学习网络进行状态估计的有效方法。

Axlam:用于边缘计算语言模型的节能加速器设计
现代语言模型,例如来自变形金刚的双向编码器表示,已彻底改变了自然语言处理(NLP)任务,但在计算上是密集的,限制了它们在边缘设备上的部署。本文介绍了针对基于编码器的语言模型量身定制的节能加速器设计,使其可以集成到移动和边缘计算环境中。与Simba启发的语言模型的数据流相关的硬件加速器设计相比,使用近似固定点的乘数,并利用高带宽内存(HBM)来实现与硬件可靠的可扩展加速器Simba相比,可以显着提高计算效率,功耗,区域和延迟。与Simba相比,Axlam可实现九倍的能量减少,减少58%的面积和1.2倍的延迟,使其适合在边缘设备中部署。Axlan的能源效率为1.8顶/W,比事实高65%,这需要在硬件上实施语言模型之前对语言模型进行预处理。本文是主题问题的一部分,“未来安全计算平台的新兴技术”。

利用超网和可学习的内核来预测各种消费者类型的消费能量
摘要 - 消费者能源预测对于管理能源消耗和计划,直接影响运营效率,降低成本,个性化的能源管理和可持续性工作至关重要。近年来,深入学习技术,尤其是LSTM和变形金刚在能源消耗的预测领域取得了巨大成功。尽管如此,这些技术在捕获综合和突然的变化方面存在困难,而且,通常仅在特定类型的消费者(例如,只有办公室,只有学校)上对它们进行检查。因此,本文提出了超能量,这是一种消费者能源预测的策略,利用超网络可用来改善适用于多样化消费者的复杂模式的建模。超网络负责预测主要预测网络的参数。由多项式和径向基函数内核组成的可学习的可自适应核纳入了增强性能。对拟议的超能量进行了评估,包括各种消费者,包括学生住宅,独立的房屋,带电动汽车充电的房屋和联排别墅。在所有消费者类型中,超能量始终超过10种其他技术,包括最先进的模型,例如LSTM,PoastionLSTM和Transformer。
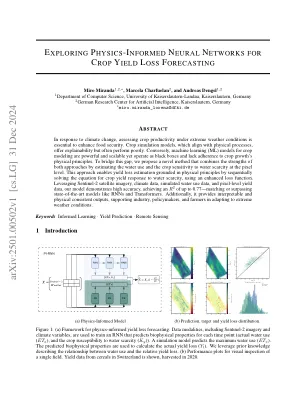
探索物理知识的神经网络以获取作物产量...
响应气候变化,评估极端天气条件下的作物生产力对于提高粮食安全至关重要。与物理过程保持一致的作物模拟模型,可提供解释性,但表现较差。相反,用于作物建模的机器学习(ML)模型具有强大的可扩展性,但可作为黑匣子,并且缺乏遵守作物生长的物理原理。为了弥合这一差距,我们提出了一种新颖的方法,该方法通过估计用水量和对像素水平的水稀缺性的敏感性来结合两种方法的优势。这种方法通过使用增强的损失函数依次解决对水稀缺性的作物产量反应的方程来实现基于物理原理的产量损失估计。利用Sentinel-2卫星图像,气候数据,模拟的用水数据和像素级产量数据,我们的模型表明了高准确性,达到了高达0.77的R 2,匹配或超过了诸如RNNS和变形金刚(RNNS and Transfors)的先例模型。此外,它还提供了可解释的和物理一致的产出,支持行业,决策者和农民适应极端天气条件。

Exhubert:通过块扩展加强休伯特,并在37个情绪数据集上进行微调
基础模型通过利用其预先训练的代表来捕获语音信号中的情感模式,在语音情感识别(SER)中表现出了巨大的希望。为了进一步提高各种语言和领域的SER性能,我们提出了一种新颖的方法。首先,我们收集了Emoset ++,这是一个全面的多语言,多种文化的语音情感语料库,具有37个数据集,150,907个类型,总持续时间为119.5小时。第二,我们介绍了exhubert,这是Hubert的增强版本,它是通过骨架扩展和对E Mo s et ++进行微调实现的。我们将每个编码器层及其权重填充,然后冻结第一个重复,集成了零零的线性层并跳过连接以保持功能并确保其适应性的能力,以便随后进行微调。我们在看不见的数据集上的评估显示了Exhubert的功效,为各种SER任务设定了新的基准标记。模型和有关E Mo S et ++的详细信息:https://huggingface.co/amiriparian/exhubert。索引术语:情感计算,语音情感识别,变形金刚,深度学习

模型 - 敏捷的元学习者用于估计
在许多学科(例如个性化医学)中,随着时间的推移估算异质治疗效果(HTE)至关重要。现有的此任务的作品主要集中在基于模型的学习者上,这些学习者适应了特定的机器学习模型和调整机制。相比之下,模型不足的学习者(所谓的元学习者)在很大程度上没有探索。在我们的论文中,我们提出了几个元学习者,这些学习者可以与型号不合时宜,因此可以与任意机器学习模型(例如变形金刚)结合使用,以随着时间的推移估算HTES。然后,我们提供了一项全面的理论分析,该分析表征了不同的学习者,并使我们能够洞悉特定的学习者何时更可取。此外,我们提出了一种新颖的IVW-DR-LEARNER,即(i)使用双重稳健(DR)和正交损失; (ii)利用我们得出的逆变量权重(IVW),这些权重稳定了DR-als。由于DR-loss中的反质量反应产物,我们的IVW减小极端轨迹,导致估计方差较低。我们的IVW-DR-LEARNER在我们的实验中取得了卓越的性能,尤其是在重叠率较低和长期视野的方案中。

重要的ai-details
1。ανάγκηκατάρτισης生成的AI模型旨在学习数据中的模式,结构和关系,然后使用这些知识来产生新颖的输出。生成AI中最受欢迎和最广泛使用的技术之一是使用神经网络,尤其是生成的对抗网络(GAN)和变形金刚。生成的AI在各个领域都有广泛的应用程序,包括:文本生成:它可以生成类似人类的文本,该文本用于聊天机器人,内容创建甚至代码生成,以帮助企业进行软件开发。图像生成:生成的AI可以创建具有艺术,娱乐和视觉效果应用的图像,绘画,甚至是深击。音乐和声音发电:它可以创作音乐,产生声音效果,甚至复制声音,这在娱乐行业和游戏中很有用。数据增强:生成AI可以生成合成数据来补充实际数据集,以帮助培训机器学习模型。建议系统:它可以根据用户的喜好为用户创建个性化的内容建议。异常检测:可以使用生成模型来识别数据中非常有用的数据中的异常值或异常。

统一的文本摘要方法
当前发生的社交媒体上基于文本的信息增加需要有效的汇总。减少文本数据是自然语言处理中最重要的任务之一,也称为文本摘要。本文通过排除的模型(包括提取模型,选择了一些整个句子和解释摘要的抽象模型)对排除和当前的摘要模型进行了文献综述。此外,它也解释了基本的统计模型,例如TF-IDF或LSA,机器学习和深度学习,并专注于基于变形金刚的模型,例如BERT或GPT,这些模型已提高了摘要质量。这些发现还显示了深度学习模型与其他传统技术之间的比较分析。摘要中的开放问题包括凝聚力,准确性和捕获长期依赖性,本文将混合动力和预训练的语言模型作为可能的解决方案。本文还指示了未来的研究领域,包括模型的效率,增强模型的事实内容以及模型的特殊目的应用。本评论为改进文本摘要方法提供了良好的背景,并使研究人员和从业人员了解当前正在做的事情以及将来可能受到影响。