
机构名称:
¥ 1.0
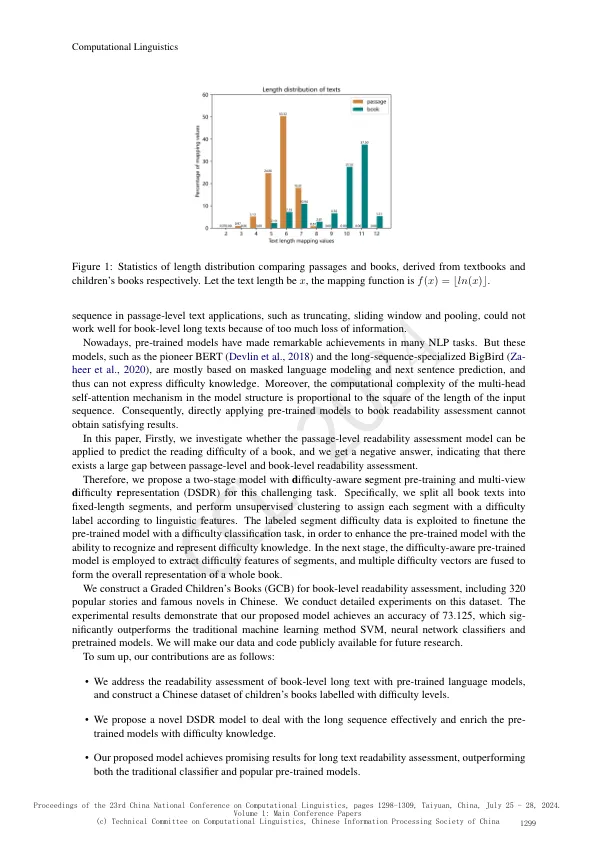
在实际教育应用中,广泛需要对书籍级长文本进行可读性评估。然而,目前大多数研究都集中在段落级可读性评估,对超长文本的处理工作很少。为了更好地处理长序列的书籍文本并利用难度知识增强预训练模型,我们提出了一种新颖的模型 DSDR、难度感知片段预训练和难度多视图表示。具体来说,我们将所有书籍分成多个固定长度的片段,并采用无监督聚类来获得难度感知片段,这些片段用于重新训练预训练模型以学习难度知识。因此,长文本通过对具有不同难度级别的多个片段向量进行平均来表示。我们构建了一个新的儿童分级读物数据集来评估模型性能。我们提出的模型取得了令人满意的结果,优于传统的 SVM 分类器和几种流行的预训练模型。此外,我们的工作为书籍级可读性评估建立了一个新的原型,为未来相关研究提供了重要的基准。
书籍级长文本的可读性评估
主要关键词




相关文件推荐





























