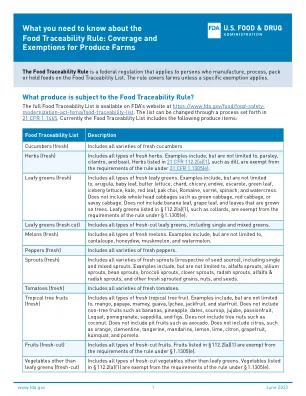
机构名称:
¥ 1.0
主要的序列传导模型基于复杂的循环或卷积神经网络,包括编码器和解码器。性能最佳的模型还通过注意力机制连接编码器和解码器。我们提出了一种新的简单网络架构 Transformer,它完全基于注意力机制,完全省去了循环和卷积。在两个机器翻译任务上的实验表明,这些模型质量优越,同时可并行性更高,并且训练时间显著减少。我们的模型在 WMT 2014 英语到德语翻译任务中获得了 28.4 BLEU,比现有最佳结果(包括集成)提高了 2 BLEU 以上。在 WMT 2014 英语到法语翻译任务中,我们的模型在八个 GPU 上训练 3.5 天后,建立了新的单模型最新 BLEU 分数 41.0,这仅仅是文献中最佳模型训练成本的一小部分。
你只需要关注
主要关键词





相关文件推荐