
机构名称:
¥ 1.0
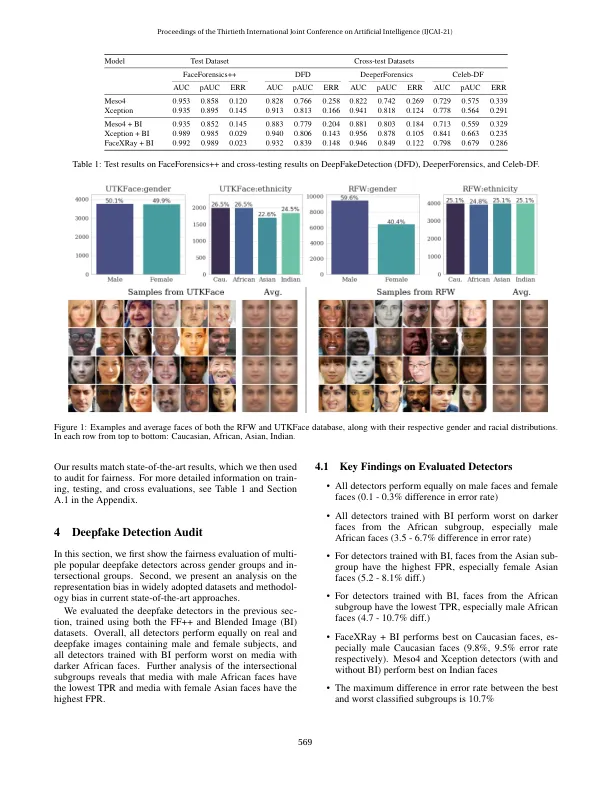
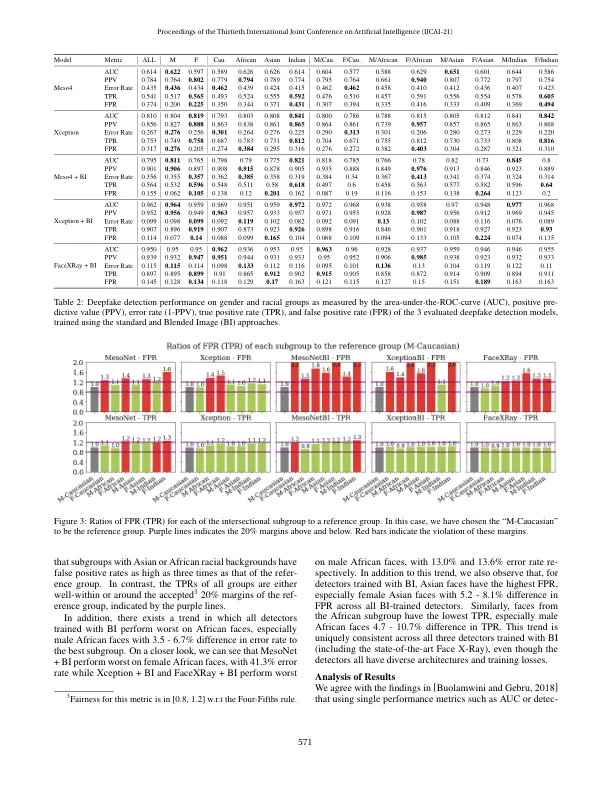
最近的研究表明,深度学习模型可以根据种族和性别等受保护的类别进行区分。在这项工作中,我们评估了深度伪造数据集和检测模型在受保护子群体中的偏差。使用按种族和性别平衡的面部数据集,我们检查了三种流行的深度伪造检测器,发现不同种族之间的预测性能存在很大差异,不同子群体之间的错误率差异高达 10.7%。仔细观察就会发现,广泛使用的 FaceForensics++ 数据集绝大多数由白种人组成,其中大多数是白种人女性。我们对深度伪造的种族分布的调查显示,用于创建深度伪造作为正面训练信号的方法往往会产生“不规则”的面孔——当一个人的脸被换到另一个不同种族或性别的人身上时。这导致检测器学习到前景面孔和假象之间的虚假相关性。此外,当使用 Face X-Rays 的混合图像 (BI) 数据集对检测器进行训练时,我们发现这些检测器会对某些种族群体(主要是亚洲女性)产生系统性歧视。
对 Deepfake 检测 AI 模型公平性的检验
主要关键词



相关文件推荐


























