
机构名称:
¥ 2.0
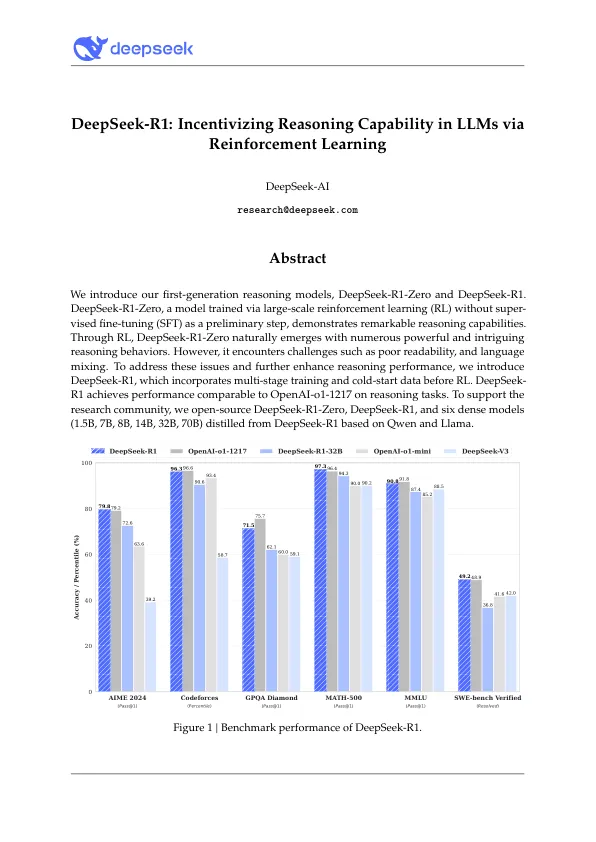
我们介绍了第一代推理模型,即DeepSeek-R1-Zero和DeepSeek-R1。DeepSeek-R1-Zero,一种通过大规模增强学习(RL)训练的模型,没有超级微调(SFT)作为初步的步骤,表现出显着的推理能力。通过RL,DeepSeek-R1-Zero自然出现,具有许多强大而有趣的推理行为。但是,它遇到了挑战,例如不良的可读性和语言混合。为了解决这些问题并进一步提高了推理性能,我们引入了DeepSeek-R1,该问题在RL之前结合了多阶段培训和冷启动数据。DeepSeek-R1在推理任务上实现与OpenAI-O1-1217相当的性能。为了支持研究社区,我们开放源DeepSeek-R1-Zero,DeepSeek-R1和六种密集的型号(1.5b,7b,8b,8b,14b,32b,32b,70b),根据Qwen和Llama蒸馏出了DeepSeek-R1。
DeepSeek-R1:通过增强学习激励LLM中的推理能力
主要关键词




相关文件推荐





























