
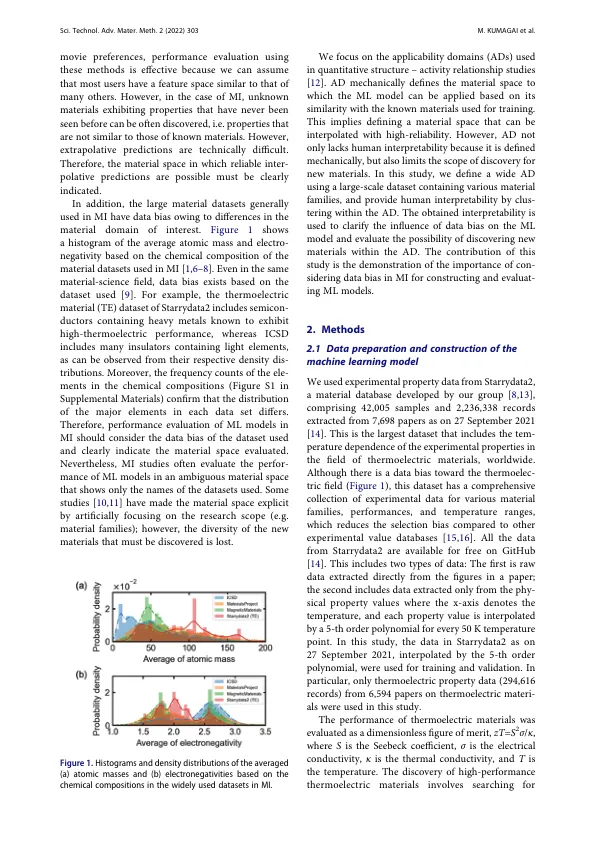
机构名称:
¥ 1.0
摘要材料信息学(MI)研究是通过大规模材料数据通过机器学习(ML)发现新材料的研究,近年来引起了人们的关注。通常,由于目标材料域的差异,MI中使用的大规模材料数据是偏差的。此外,关于MI的大多数研究尚未清楚地证明数据偏差对ML模型的影响。在这项研究中,我们通过结合了以前由我们小组开发的StarryData2材料数据库中的大规模实验性能数据的概念来阐明数据偏差对ML模型的影响。结果表明,数据偏差会影响ML模型进行的预测的错误和可靠性。与在域外制造的域相比,应用程序能力域内的ML模型的预测非常可靠。这表明构造的ML模型可以可靠发现的物质空间有限。尽管如此,我们将ML模型应用于包含各种材料类别的大型数据集,并发现可以在有限的空间内提出类似于已知材料的新材料。因此,我们的发现证明了在MI中构建和评估ML模型时考虑数据偏差的重要性。
使用实验性属性数据
主要关键词




相关文件推荐





























