机构名称:
¥ 1.0
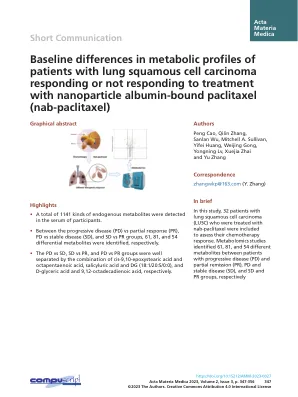
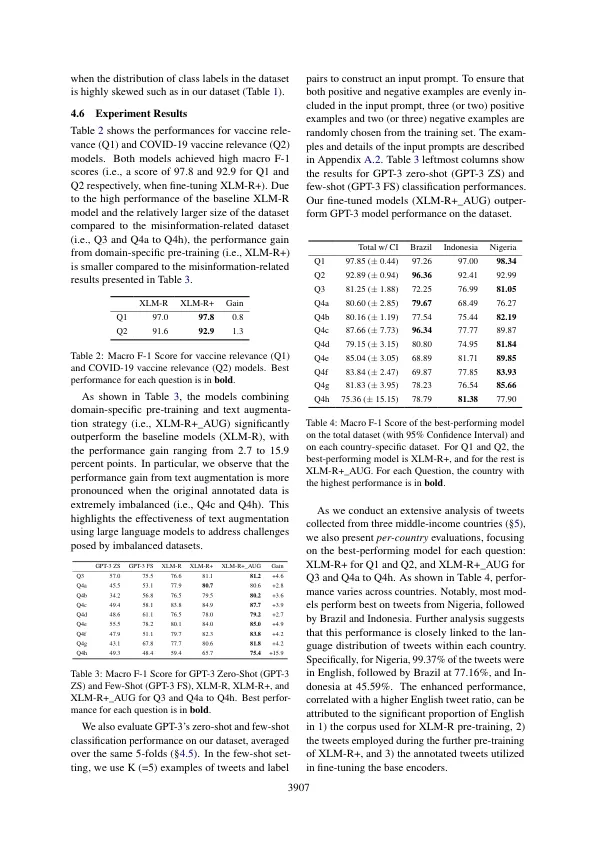
本文介绍了COVID-19的多语言数据集,包括来自三个中等收入国家的带注释的推文:巴西,印度尼西亚和尼日利亚。专业精心策划的数据集包括5,952条推文的注释,评估了它们与Covid-19疫苗的相关性,存在错误信息以及错误信息的主题。为了解决域规格,低资源设置和数据不平衡提出的挑战,我们采用了两种方法,用于开发Covid-19疫苗错误信息传播模型:使用大型语言模型使用域特异性的预训练和文本增强。与基线模型相比,我们最佳的错误信息检测模式显示了宏F1得分的2.7到15.9个百分点的改进。此外,我们在2020年至2022年之间的1900万个未标记的推文的大规模研究中应用了错误信息检测模型,展示了我们的数据集和模型在多个国家和语言中检测和分析疫苗误解的实际应用。我们的分析表明,新的Covid-19案件数量的百分比变化与巴西和印度尼西亚的交错方式与Covid-19疫苗的错误信息率呈正相关,并且在这三个国家之间存在明显的正相关。
COVID-19
主要关键词




相关文件推荐