机构名称:
¥ 2.0
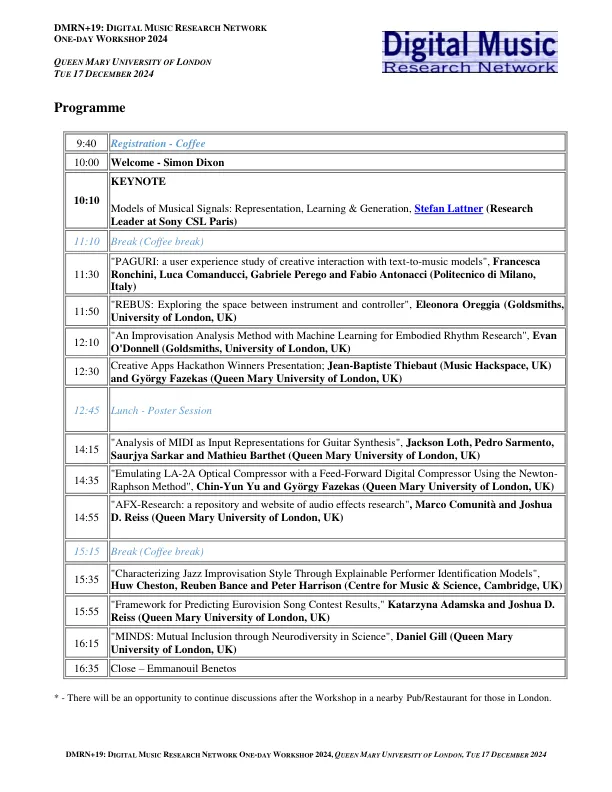
tittle:音乐信号的模型:表示,学习与生成摘要:低级音频表示和高级表示学习是音乐分析和综合的核心。因此,演讲将介入索尼CSL在音频表示方面的一些以前的作品,涵盖了不同的概念和用例。学习一阶和二阶基础函数以获得所需的不变,并研究了为生成,高级表示的自我监督学习和音频编解码器的低级音频表示。最后,将讨论音乐音频综合,从gan到潜在的扩散,再到连续自回旋模型的最新进步。bio:斯特凡·拉特纳(Stefan Lattner)担任索尼CSL巴黎音乐团队的研究员领导者,他专注于音乐制作,音乐信息检索和代表性学习的生成AI。在奥地利的维也纳人工智能研究所和计算感知研究所林兹(Linz)的研究所研究之后,他于2019年在奥地利林茨的约翰内斯开普勒大学(JKU)获得博士学位。他的研究以音乐结构的建模为中心,包括转换学习和计算相对音调感知。他目前的兴趣包括音乐创作,现场演出和音乐中信息理论的人力计算机互动。他专门研究潜在的扩散,自我监督的学习,生成序列模型,计算短期记忆和人类感知模型。
数字音乐研究网络一日研讨会2024
主要关键词




相关文件推荐