
机构名称:
¥ 1.0
术语 A = 动作空间 a = 动作 a ,b = 机械手长度属性,m B = 值分布箱的数量 C = 科里奥利矩阵 dt = 目标上的对接口位置,m E = 期望 h = 角动量,kg ⋅ m2 ∕ s I = 转动惯量,kg ⋅ m2 J = 总预期奖励 K = 参与者数量 L = 损失函数 l = 线性动量,kg ⋅ m ∕ s M = 质量矩阵 M = 小批量大小 m = 质量,kg N = N 步返回长度 N = 正态分布 p = 位置,m R = 重放缓冲区大小 r = 奖励 u = 控制力度 v = 速度,m ∕ s X = 状态空间 x = 总状态;特定状态,下标为 c 或 tx = x 方向的位置,m Y = 目标值分布 y = y 方向的位置,m Z ϕ = 具有参数 ϕ 的价值神经网络 α = 策略网络学习率 β = 价值网络学习率 γ = 未来奖励的折扣因子 ϵ = 权重平滑参数 π θ = 具有参数 θ ϕ 0 或 θ 0 的策略神经网络 = ϕ 或 θ ϕ 的指数平滑版本,q = 角度,度 σ = 探索噪声标准差 ω = 角速率,rad ∕ s
使用基于深度强化学习的引导进行航天器机器人捕获的实验室实验
主要关键词




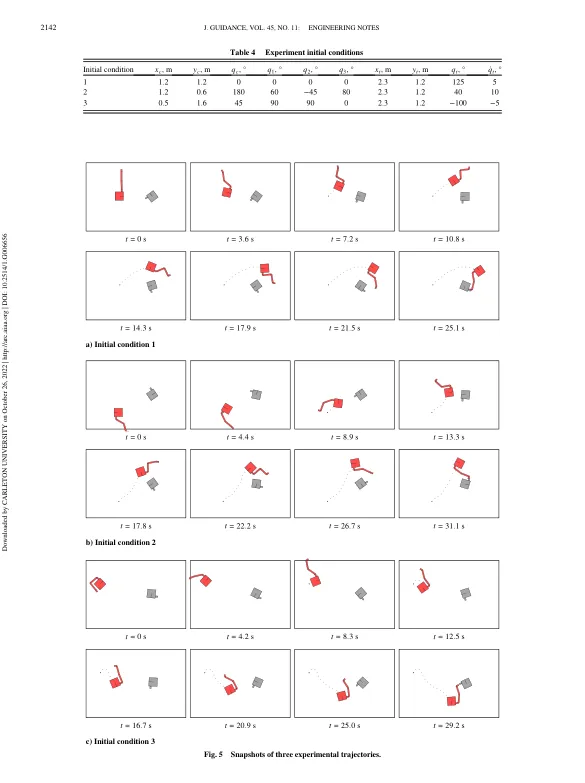
相关文件推荐





























