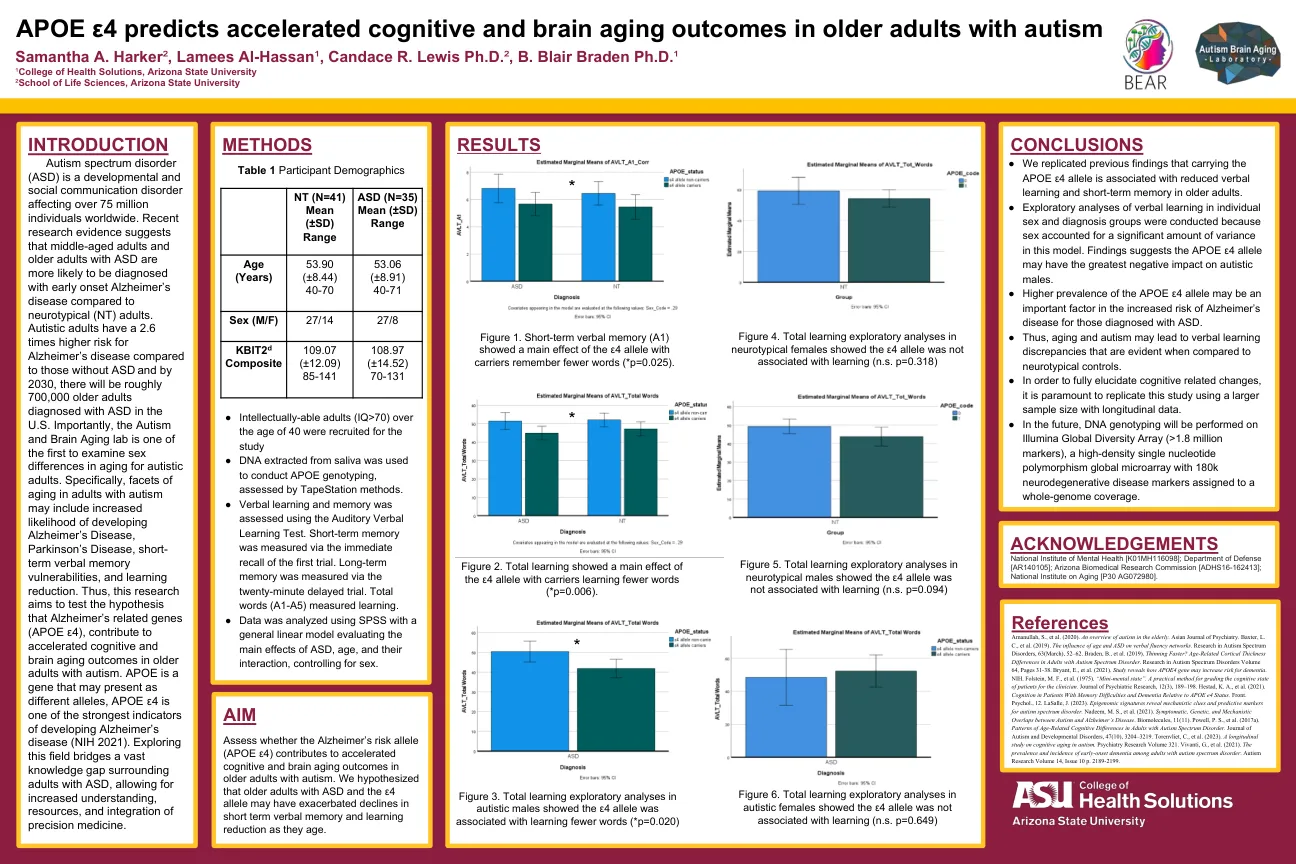
机构名称:
¥ 1.0
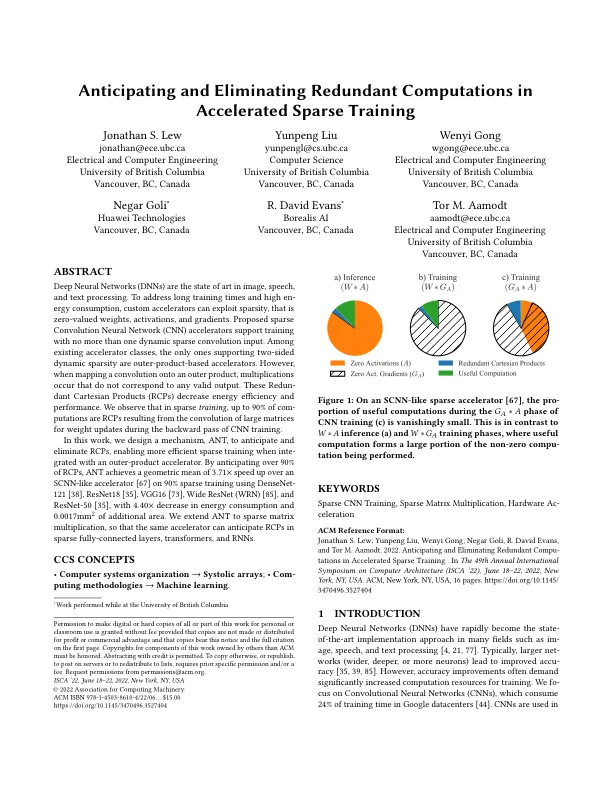
深度神经网络 (DNN) 是图像、语音和文本处理的最新技术。为了解决训练时间长和能耗高的问题,自定义加速器可以利用稀疏性,即零值权重、激活和梯度。提出的稀疏卷积神经网络 (CNN) 加速器支持使用不超过一个动态稀疏卷积输入进行训练。在现有的加速器类别中,唯一支持双面动态稀疏性的是基于外积的加速器。然而,当将卷积映射到外积时,会发生与任何有效输出都不对应的乘法。这些冗余笛卡尔积 (RCP) 降低了能源效率和性能。我们观察到在稀疏训练中,高达 90% 的计算都是 RCP,它们是由 CNN 训练后向传递期间大矩阵的卷积产生的,用于更新权重。在本文中,我们设计了一种机制 ANT 来预测和消除 RCP,与外积加速器结合使用时可以实现更高效的稀疏训练。通过预测超过 90% 的 RCP,在使用 DenseNet- 121 [ 38 ]、ResNet18 [ 35 ]、VGG16 [ 73 ]、Wide ResNet (WRN) [ 85 ] 和 ResNet-50 [ 35 ] 的 90% 稀疏训练中,ANT 比类 SCNN 加速器 [67] 实现了 3.71 倍的几何平均速度提升,能耗降低了 4.40 倍,面积增加了 0.0017 平方毫米。我们将 ANT 扩展到稀疏矩阵乘法,以便同一个加速器可以预测稀疏全连接层、Transformer 和 RNN 中的 RCP。
预测和消除加速稀疏训练中的冗余计算
主要关键词




相关文件推荐