
机构名称:
¥ 1.0
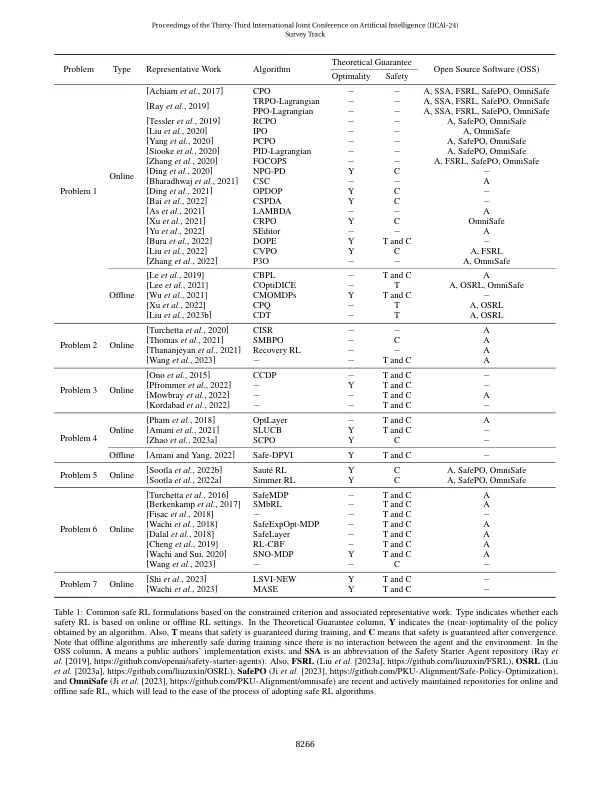
在将强化学习(RL)应用于现实世界问题时至关重要。作为一种疾病,Safe RL已成为一种基本而有力的范式,用于优化代理人的政策,同时纳入安全概念。一种安全的RL方法是基于一个受约束的标准,该标准旨在最大程度地提高预期的累积奖励。尽管最近努力提高RL的安全性,但对该领域的系统理解仍然很困难。这一挑战源于约束表示的多样性和对其相互关系的探索。为了弥合这一知识差距,我们对代表约束表述进行了全面的综述,以及专门针对每个公式设计的算法选择的选择。此外,我们阐明了理论基础,这些基础揭示了共同问题之间的数学相互关系。我们在讨论安全加强学习研究的当前状态和未来方向的讨论中结束。
对安全强化学习中约束配方的调查
主要关键词




相关文件推荐





























