
机构名称:
¥ 5.0
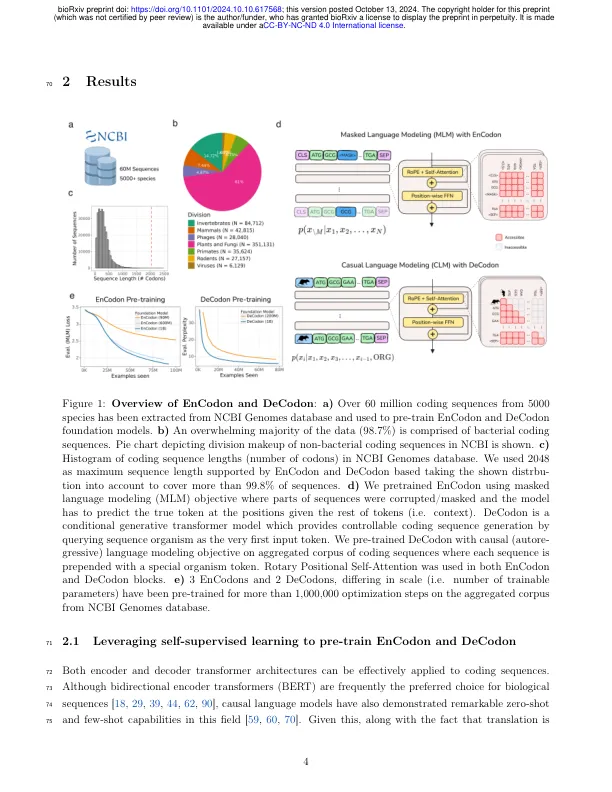
图1:Encodon和Decodon的概述:A)已从NCBI基因组数据库中提取了5000种物种的6000万个编码序列,并用于预先培训Encodon和Decodon基础模型。b)绝大多数数据(98.7%)由细菌编码序列组成。显示了NCBI中非细菌编码序列的分裂构成的饼图。c)NCBI基因组数据库中编码序列长度(密码子数)的直方图。我们将2048用作由Encodon和Decodon支持的最大序列长度,并考虑到所示的分散量以覆盖超过99.8%的序列。d)我们使用蒙版语言建模(MLM)目标仔细研究了Encodon,其中序列的一部分被损坏/掩盖了,并且该模型必须在给定其余的令牌(即上下文)。decodon是一种有条件的生成变压器模型,它通过将序列生物体作为第一个输入令牌来提供可控的编码序列生成。我们在汇总的编码序列中,用因果(自动性)语言建模目标进行了训练,其中每个序列都用特殊的有机体令牌培养。旋转位置自我注意事项均在Encodon和Decodon块中使用。e)3个ecdodons和2个解码,比例不同(即可训练参数的数量)已在NCBI基因组数据库的汇总语料库上进行了超过1,000,000个优化步骤的预训练。
一套基础模型捕获了密码子之间的上下文相互作用
主要关键词




相关文件推荐





























