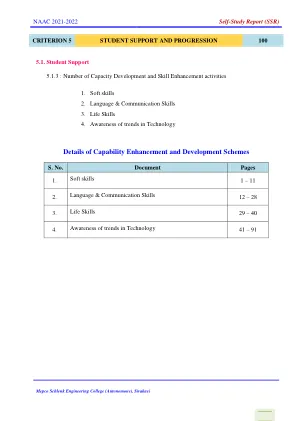
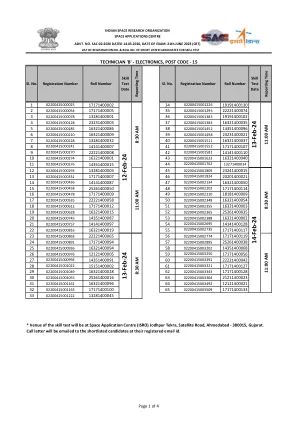
机构名称:
¥ 1.0
摘要:人形机器人由于其灵活性和类似人类的文化而在各种环境和任务中跨越人类具有巨大潜力。然而,鉴于高维动作空间和双足体系统的固有不稳定,全身控制仍然是一个重大挑战。以前的作品通常依赖于具有计算昂贵的优化的精确动态模型,也可以通过广泛的奖励调整进行特定于任务的培训。在这项工作中,我们介绍了Skillblender,这是一个层次的强化学习框架,首先使用预先设计的密集奖励开发了一系列原始技能,然后重新使用并融合了这些技能,以完成更复杂的新任务,需要最小的特定于任务的奖励工程。我们对两个复杂的机车操作任务进行的模拟实验表明,我们的方法显着胜过所有基础,同时自然地将行为正规化以避免奖励黑客攻击,从而导致更可行的人类样运动。网站:https://sites.google.com/view/wcbm-skillblender/。
技能培训者:通过技能混合
主要关键词




相关文件推荐